python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息
**如果看不清楚
按照以下步骤:**
1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息)
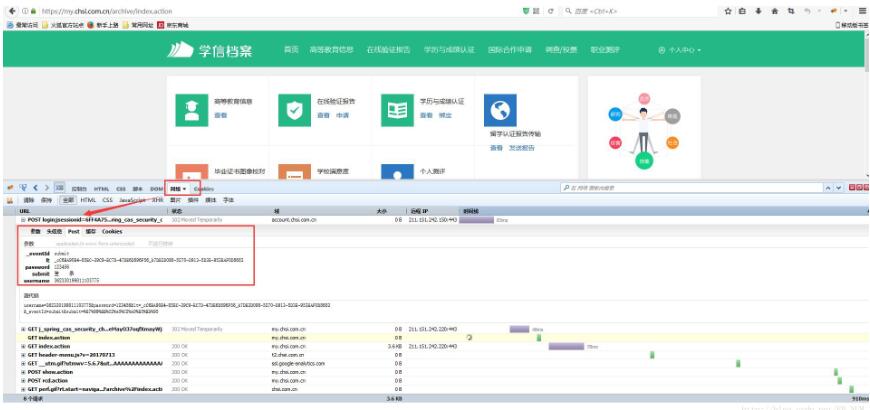
import requests
from bs4 import BeautifulSoup
from http import cookies
import urllib
import http.cookiejar
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0',
'Referer':'https://account.chsi.com.cn/passport/login?service=https://my.chsi.com.cn/archive/j_spring_cas_security_check',
}
session = requests.Session()
session.headers.update(headers)
username = 'xxx'
password = 'xxx'
url = 'https://account.chsi.com.cn/passport/login?service=https://my.chsi.com.cn/archive/j_spring_cas_security_check'
def login(username,password,lt,_eventId='submit'): #模拟登入函数
#构造表单数据
data = { #需要传去的数据
'_eventId':_eventId,
'lt':lt,
'password':password,
'submit':u'登录',
'username':username,
}
html = session.post(url,data=data,headers=headers)
def get_lt(url): #解析登入界面_eventId
html = session.get(url)
#获取 lt
soup = BeautifulSoup(html.text,'lxml',from_encoding="utf-8")
lt=soup.find('input',type="hidden")['value']
return lt
lt = get_lt(url)#获取登录form表单信息 以学信网为例
login(username,password,lt)
login_url = 'https://my.chsi.com.cn/archive/gdjy/xj/show.action'
per_html = session.get(login_url)
soup = BeautifulSoup(per_html.text,'lxml',from_encoding="utf-8")
print(soup)
for tag in soup.find_all('table',class_='mb-table'):
print(tag)
for tag1 in tag.find_all('td'):
title= tag1.get_text();
print(title)
以上这篇python 爬取学信网登录页面的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
python动态网页批量爬取
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页.我使用的是学信网,好了,网站截图如下: 网站的代码如下: <form method="get" name="form1" id="form1" action="/cet/query"> <table border=&qu
-
python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息 **如果看不清楚 按照以下步骤:** 1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息) import requests from bs4 import BeautifulSoup from http import cookies import urllib impo
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/
-
使用Python爬取最好大学网大学排名
本文实例为大家分享了Python爬取最好大学网大学排名的具体代码,供大家参考,具体内容如下 源代码: #-*-coding:utf-8-*- ''''' Created on 2017年3月17日 @author: lavi ''' import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status r.encodi
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi
-
python爬取网易云音乐排行榜实例代码
目录 网易云音乐排行榜歌曲及评论爬取 一.模拟登录 二.排行榜数据爬取 三.排行榜评论获取 总结 网易云音乐排行榜歌曲及评论爬取 主要注意问题:selenium 模拟登录.iframe标签定位.页面元素提取. 在利用selenium定位元素并取值的过程中遇到问题.比如xpath正确但无法定位,在进行翻页提取评论的过程中,利用selenium似乎不能提取不同页的数据,比如,明明定位的第三页的评论数据,而只能返回第一页的评论数据. 一.模拟登录 selenium 定位元素模拟人的操作进行登录,直接上
-
Python爬取肯德基官网ajax的post请求实现过程
目录 准备工作 分析 程序入口 url组成数据定位 构造url 参数 post请求 标头获取(防止反爬的一种手段) 请求对象定制 获取网页源码 获取响应中的页面的源码,下载数据 全部代码 爬取后结果 准备工作 查看肯德基官网的请求方法:post请求. X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求 通过这两个准备步骤,明确本次爬虫目标: ajax的post请求肯德基官网 获取上海肯德基地点前10页. 分析 获取上海肯德基地点前10页,那就需要先对
-
python scrapy拆解查看Spider类爬取优设网极细讲解
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: import scrapy class UiSpider(scrapy.Spider): name = 'ui' allowed_domains = ['www.uisdc.com'] start_urls =