Python爬取肯德基官网ajax的post请求实现过程
目录
- 准备工作
- 分析
- 程序入口
- url组成数据定位
- 构造url
- 参数
- post请求
- 标头获取(防止反爬的一种手段)
- 请求对象定制
- 获取网页源码
- 获取响应中的页面的源码,下载数据
- 全部代码
- 爬取后结果

准备工作
查看肯德基官网的请求方法:post请求。
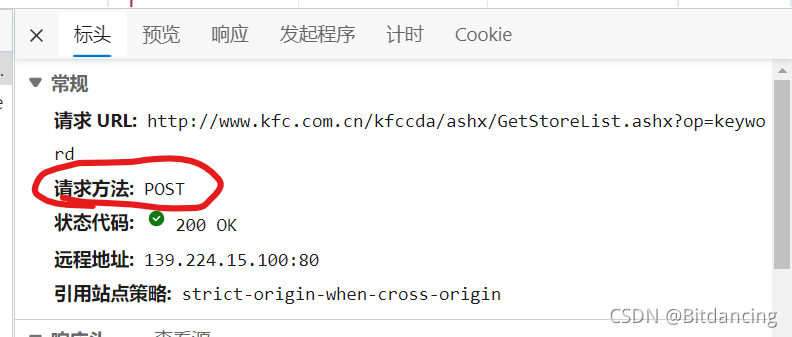
X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求
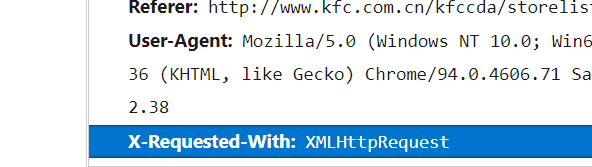
通过这两个准备步骤,明确本次爬虫目标:
ajax的post请求肯德基官网 获取上海肯德基地点前10页。
分析
获取上海肯德基地点前10页,那就需要先对每页的url进行分析。
第一页
# page1 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cname: 上海 # pid: # pageIndex: 1 # pageSize: 10
第二页
# page2 # http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname # POST # cname: 上海 # pid: # pageIndex: 2 # pageSize: 10
第三页依次类推。
程序入口
首先回顾urllib爬取的基本操作:
# 使用urllib获取百度首页的源码
import urllib.request
# 1.定义一个url,就是你要访问的地址
url = 'http://www.baidu.com'
# 2.模拟浏览器向服务器发送请求 response响应
response = urllib.request.urlopen(url)
# 3.获取响应中的页面的源码 content内容
# read方法 返回的是字节形式的二进制数据
# 将二进制数据转换为字符串
# 二进制-->字符串 解码 decode方法
content = response.read().decode('utf-8')
# 4.打印数据
print(content)
1.定义一个url,就是你要访问的地址
2.模拟浏览器向服务器发送请求 response响应
3.获取响应中的页面的源码 content内容
if __name__ == '__main__':
start_page = int(input('请输入起始页码: '))
end_page = int(input('请输入结束页码: '))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载数据
down_load(page, content)
对应的,我们在主函数中也类似声明方法。
url组成数据定位
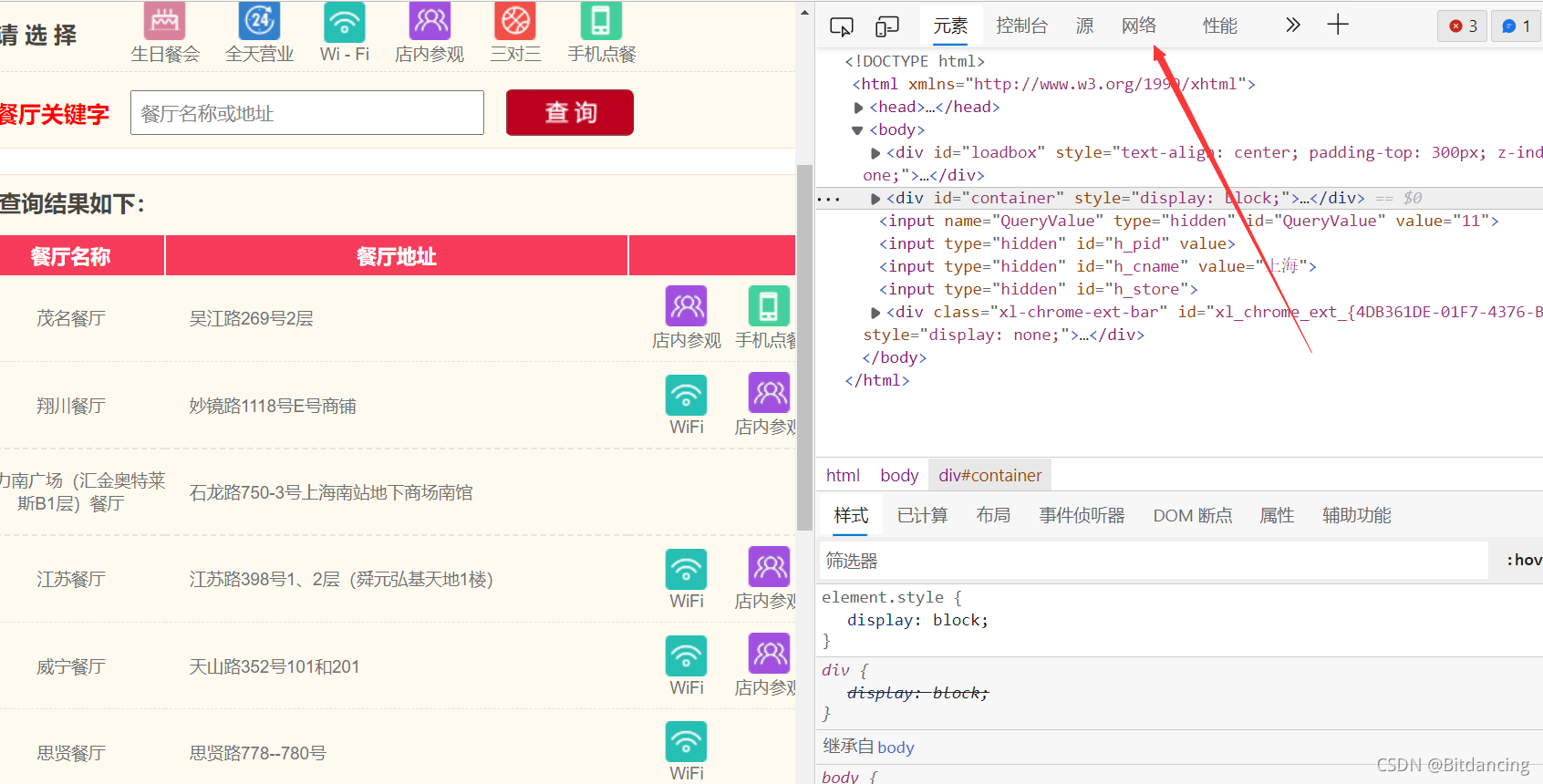
爬虫的关键在于找接口。对于这个案例,在预览页可以找到页面对应的json数据,说明这是我们要的数据。
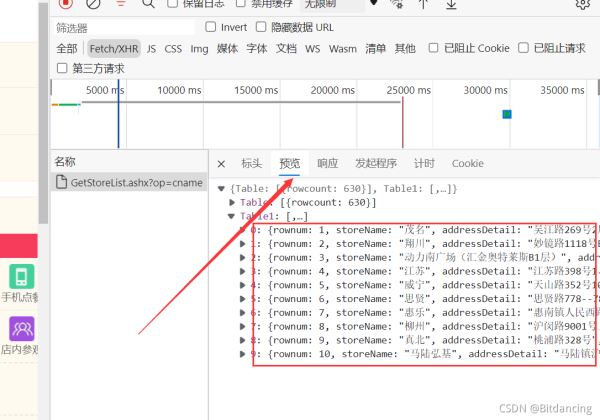
构造url
不难发现,肯德基官网的url的一个共同点,我们把它保存为base_url。
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
参数
老样子,找规律,只有'pageIndex'和页码有关。
data = {
'cname': '上海',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
post请求
- post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
- 编码之后必须调用encode方法
- 参数放在请求对象定制的方法中:post的请求的参数,是不会拼接在url后面的,而是放在请求对象定制的参数中
所以将data进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
标头获取(防止反爬的一种手段)

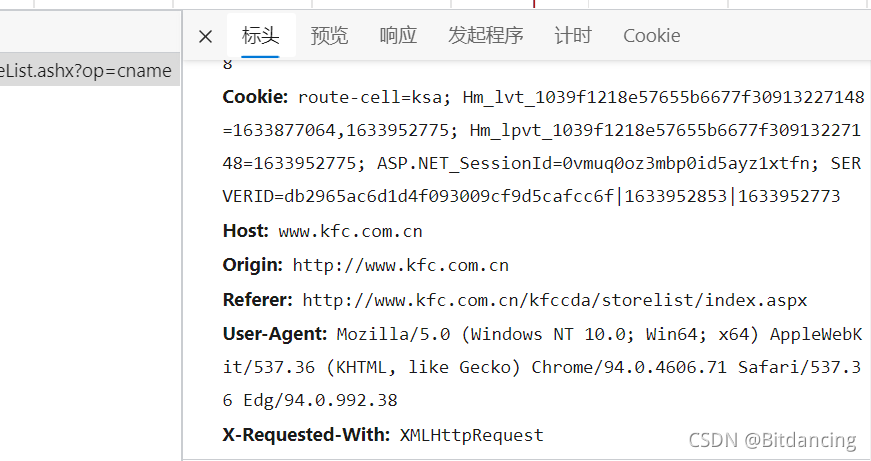
即 响应头中UA部分。
User Agent,用户代理,特殊字符串头,使得服务器能够识别客户使用的操作系统及版本,CPU类型,浏览器及版本,浏览器内核,浏览器渲染引擎,浏览器语言,浏览器插件等。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38'
}
请求对象定制
参数,base_url,请求头都准备得当后,就可以进行请求对象定制了。
request = urllib.request.Request(base_url, headers=headers, data=data)
获取网页源码
把request请求作为参数,模拟浏览器向服务器发送请求 获得response响应。
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
获取响应中的页面的源码,下载数据
使用 read()方法,得到字节形式的二进制数据,需要使用 decode进行解码,转换为字符串。
content = response.read().decode('utf-8')
然后我们将下载得到的数据写进文件,使用 with open() as fp 的语法,系统自动关闭文件。
def down_load(page, content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
全部代码
# ajax的post请求肯德基官网 获取上海肯德基地点前10页
# page1
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# POST
# cname: 上海
# pid:
# pageIndex: 1
# pageSize: 10
# page2
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# POST
# cname: 上海
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request, urllib.parse
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '上海',
'pid': '',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38'
}
request = urllib.request.Request(base_url, headers=headers, data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page, content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf-8') as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码: '))
end_page = int(input('请输入结束页码: '))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载数据
down_load(page, content)
爬取后结果
以上就是Python爬取肯德基官网ajax的post请求实现过程的详细内容,更多关于Python爬取肯德基官网ajax的post请求的资料请关注我们其它相关文章!
相关推荐
-
django ajax发送post请求的两种方法
django ajax发送post请求的两种方法,具体内容如下所述: 第一种:将csrf_token放在from表单里 <script> function add_competion_goods() { $.ajax({ url: "{% url 'add_competition_goods' %}", type: "POST", dataType: "json", data: $('#add_competition_goods_fr
-

python爬虫 基于requests模块发起ajax的get请求实现解析
基于requests模块发起ajax的get请求 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据 用抓包工具捉取 使用ajax加载页面的请求 鼠标往下下滚轮拖动页面,会加载更多的电影信息,这个局部刷新是当前页面发起的ajax请求, 用抓包工具捉取页面刷新的ajax的get请求,捉取滚轮在最底部时候发起的请求 这个get请求是本次发起的请求的url ajax的get请求携带参数 获取响应内容不再是页面数据,是json字符串,是通过异步请求获取的电影
-
python爬取Ajax动态加载网页过程解析
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 :网站根据IP地址访问频率进行反爬,短时间内进制IP访问 解决方案: 1.构造自己IP代理池,每次访问随机选择代理,经常更新代理池 2.购买开放代理或私密代理IP 3.降低爬取的速度 3.User-Agent限制 :类似于IP限制 解决方案: 构造自己的User-Agent池,每次访问随机选择 5.
-
Python3爬虫中关于Ajax分析方法的总结
这里还以前面的微博为例,我们知道拖动刷新的内容由Ajax加载,而且页面的URL没有变化,那么应该到哪里去查看这些Ajax请求呢? 1. 查看请求 这里还需要借助浏览器的开发者工具,下面以Chrome浏览器为例来介绍. 首先,用Chrome浏览器打开微博的链接https://m.weibo.cn/u/2830678474,随后在页面中点击鼠标右键,从弹出的快捷菜单中选择"检查"选项,此时便会弹出开发者工具,如图6-2所示: 此时在Elements选项卡中便会观察到网页的源代码,右侧便是节
-
Python的flask接收前台的ajax的post数据和get数据的方法
ajax向后台发送数据: ①post方式 ajax: @app.route("/find_worldByName",methods=['POST']) type:'post', data:{'cname':cname,'continent':continent}, 这是post方式传值 那么在后台接收就是:(使用request的form方法) continent = request.form.get("continent") cname = request.form
-
Python爬取肯德基官网ajax的post请求实现过程
目录 准备工作 分析 程序入口 url组成数据定位 构造url 参数 post请求 标头获取(防止反爬的一种手段) 请求对象定制 获取网页源码 获取响应中的页面的源码,下载数据 全部代码 爬取后结果 准备工作 查看肯德基官网的请求方法:post请求. X-Requested-With: XMLHttpRequest 判断得肯德基官网是ajax请求 通过这两个准备步骤,明确本次爬虫目标: ajax的post请求肯德基官网 获取上海肯德基地点前10页. 分析 获取上海肯德基地点前10页,那就需要先对
-
利用python爬取散文网的文章实例教程
本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍: 效果图如下: 配置python 2.7 bs4 requests 安装 用pip进行安装 sudo pip install bs4 sudo pip install requests 简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容 find_all返
-
python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息 **如果看不清楚 按照以下步骤:** 1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息) import requests from bs4 import BeautifulSoup from http import cookies import urllib impo
-
python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comments(res): comments_json = json.loads(res.text) hot_comments = comments_json['hotComments'] with open("hotcmments.txt", 'w', encoding = 'utf-8') a
-
使用Python爬取最好大学网大学排名
本文实例为大家分享了Python爬取最好大学网大学排名的具体代码,供大家参考,具体内容如下 源代码: #-*-coding:utf-8-*- ''''' Created on 2017年3月17日 @author: lavi ''' import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status r.encodi
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
python 爬取天气网卫星图片
项目地址: https://github.com/MrWayneLee/weather-demo 代码部分 下载生成文件功能 # 下载并生成文件 def downloadImg(imgDate, imgURLs, pathName): a,s,f = 0,0,0 timeStart = time.time() while a < len(imgURLs): req = requests.get(imgURLs[a]) imgName = str(imgURLs[a])[-13:-9] print
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/