使用maven实现有关Jsoup简单爬虫的步骤
一、Jsoup的简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据
二、我们可以利用Jsoup做什么
2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据,
2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本
2.3从而使我们输出我们想要的整洁文本
三、利用Jsoup爬取某东示例

可以从图中看到,成功爬取某东的女装热门销量从高到低的标题,从而可以分析到销量高(或者是综合排序)在前列的标题名称。从而可以剖析出热门商品的命名规范。
四、Jsoup用法
4.1先创建maven工程,在maven工程上注入依赖
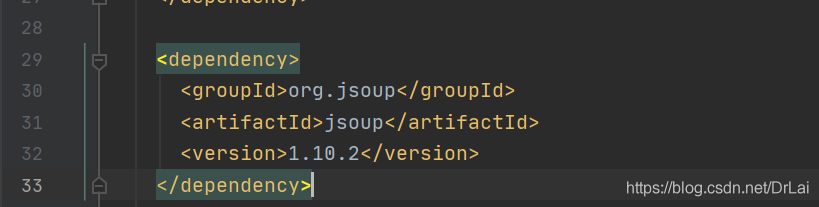
4.2注入依赖后需要导入依赖,否则在程序中使用Jsoup会全部报错。
4.3利用JSP的知识找出目标元素
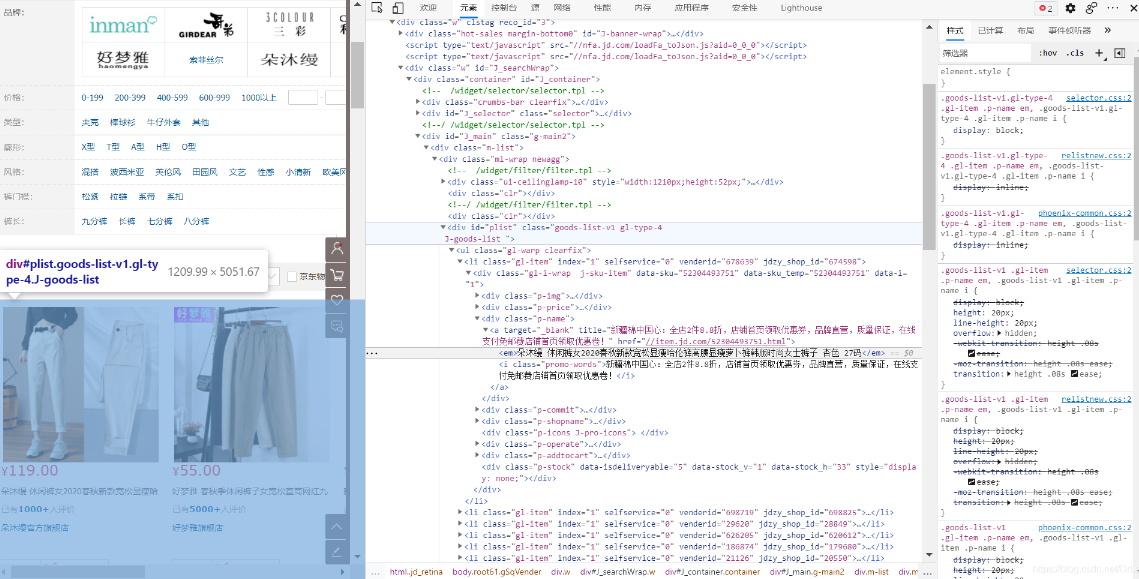
如在某东界面我们发现, 控制目标页面的ID为"plist",则我们使用
getElementById("plist");方法去获取到他的ID
接着获取目标标题,可以由上图分析得,标题是由<em>标签所控制,因此我们需要用到
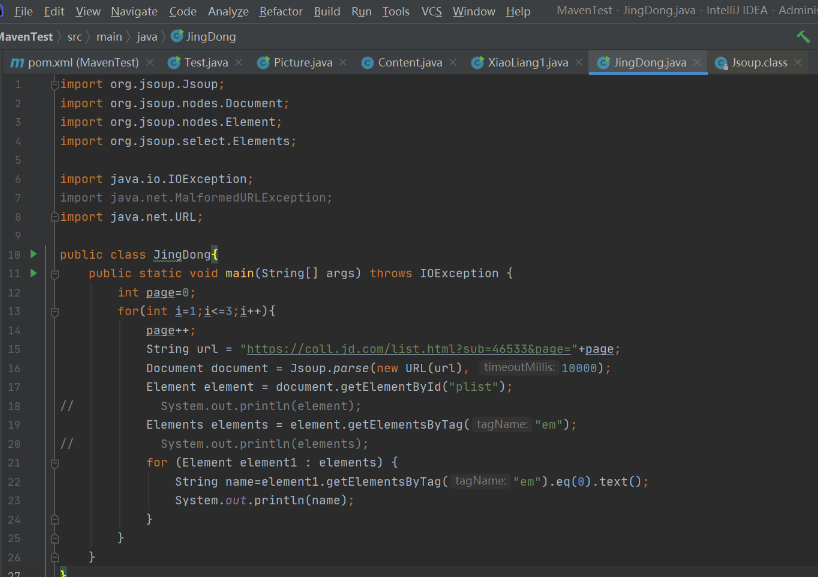
getElementsByTag("em");去捕捉到em的部分
最后循环输出他的部分即可。

五、总结
Jsoup只能应用于简单的页面捕捉,在实际开发中许多网站采用Ajax技术等使得模块在动态变化抑或是有反爬虫技术,因此本技术有局限性。熟悉前端jsp技术的同学应该会游刃有余。
最后附上所有代码
相关推荐
-
java通过Jsoup爬取网页过程详解
这篇文章主要介绍了java通过Jsoup爬取网页过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,导入依赖 <!--java爬虫--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.3</version> </depe
-

Java使用httpRequest+Jsoup爬取红蓝球号码
目录 1.Jsoup介绍 1.1.简介 1.2.Jsoup的主要功能 2.源网站及页面元素分析 2.1.号码源 2.2.dom元素分析 3.代码实现 1.Jsoup介绍 1.1.简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. 1.2.Jsoup的主要功能 1.从一个URL,文件或字符串中解析HTML 2.使用DOM或CSS选择器来查找.取出数据 3
-
Java 爬虫工具Jsoup详解
Java 爬虫工具Jsoup详解 Jsoup是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址.HTML 文本内容.它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据. jsoup 的主要功能如下: 1. 从一个 URL,文件或字符串中解析 HTML: 2. 使用 DOM 或 CSS 选择器来查找.取出数据: 3. 可操作 HTML 元素.属性.文本: jsoup 是基于 MIT 协议发布的,可放心使用于商业项目. js
-
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1.需求及配置 需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格. 使用Maven项目,log4j记录日志,日志仅导出到控制台. Maven依赖如下(pom.xml) <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId>
-
使用maven实现有关Jsoup简单爬虫的步骤
一.Jsoup的简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 二.我们可以利用Jsoup做什么 2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据, 2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本 2.3从而使我们输出我们想要的整洁文本 三.利用Jsoup爬取某东示例 可以从图中看到,成功爬取某东的女装热门销量从高到低的
-
Java 使用maven实现Jsoup简单爬虫案例详解
一.Jsoup的简介 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据 二.我们可以利用Jsoup做什么 2.1从URL,文件或字符串中刮取并解析HTML查找和提取数据, 2.2使用DOM遍历或CSS选择器操纵HTML元素,属性和文本 2.3从而使我们输出我们想要的整洁文本 三.利用Jsoup爬
-
C#简单爬虫案例分享
本文实例为大家分享了C#简单爬虫案例,供大家参考,具体内容如下 using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Text; using System.Text.RegularExpressions; using System.Threading.Tasks; namespace ConsoleApplication1 { class Program
-
Java实现爬虫给App提供数据(Jsoup 网络爬虫)
一.需求 最近基于 Material Design 重构了自己的新闻 App,数据来源是个问题. 有前人分析了知乎日报.凤凰新闻等 API,根据相应的 URL 可以获取新闻的 JSON 数据.为了锻炼写代码能力,笔者打算爬虫新闻页面,自己获取数据构建 API. 二.效果图 下图是原网站的页面 爬虫获取了数据,展示到 APP 手机端 三.爬虫思路 关于App 的实现过程可以参看这几篇文章,本文主要讲解一下如何爬虫数据. Android下录制App操作生成Gif动态图的全过程 :http://www
-
python妹子图简单爬虫实例
本文实例讲述了python妹子图简单爬虫实现方法.分享给大家供大家参考.具体如下: #!/usr/bin/env python #coding: utf-8 import urllib import urllib2 import os import re import sys #显示下载进度 def schedule(a,b,c): ''''' a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 ''' per = 100.0 * a * b / c if per > 100 : per
-
基于node.js制作简单爬虫教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息. 思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地. 步骤一:安装nod
-
python编写简单爬虫资料汇总
爬虫真是一件有意思的事儿啊,之前写过爬虫,用的是urllib2.BeautifulSoup实现简单爬虫,scrapy也有实现过.最近想更好的学习爬虫,那么就尽可能的做记录吧.这篇博客就我今天的一个学习过程写写吧. 一 正则表达式 正则表达式是一个很强大的工具了,众多的语法规则,我在爬虫中常用的有: . 匹配任意字符(换行符除外) * 匹配前一个字符0或无限次 ? 匹配前一个字符0或1次 .* 贪心算法 .*? 非贪心算法 (.*?) 将匹配到的括号中的结果输出 \d 匹配数字 re.S 使得.可
-
php实现简单爬虫的开发
有时候因为工作.自身的需求,我们都会去浏览不同网站去获取我们需要的数据,于是爬虫应运而生,下面是我在开发一个简单爬虫的经过与遇到的问题. 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的.我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读. 按照个人习惯,我首先要写一个界面,理清下思路. 1.去不同网站.那么我们需要一个url输入框. 2.找特定关键字的文章.那么我们需要一个文章标题输入框. 3.获取文章链接.那么我们需要一个搜索结果的显示容器. <di
-
PHP实现简单爬虫的方法
本文实例讲述了PHP实现简单爬虫的方法.分享给大家供大家参考.具体如下: <?php /** * 爬虫程序 -- 原型 * * 从给定的url获取html内容 * * @param string $url * @return string */ function _getUrlContent($url) { $handle = fopen($url, "r"); if ($handle) { $content = stream_get_contents($handle, 1024
-
python使用tornado实现简单爬虫
本文实例为大家分享了python使用tornado实现简单爬虫的具体代码,供大家参考,具体内容如下 代码在官方文档的示例代码中有,但是作为一个tornado新手来说阅读起来还是有点困难的,于是我在代码中添加了注释,方便理解,代码如下: # coding=utf-8 #!/usr/bin/env python import time from datetime import timedelta try: from HTMLParser import HTMLParser from urlparse