Python办公自动化解决world文件批量转换
目录
- python-docx 库简介
- 读取 Word
- 写入 Word
- Word 转 pdf
- 最后的话
只要是简单重复的工作,就想办法用 Python 来帮你解决吧,人生苦短,你需要 Python。
Word 是办公软件中使用频率非常高的软件之一了,假如你需要调整 100 个 Word 文档的格式保持统一,或者要把 100 个 Word 全部转换为 pdf,那么你就需要 Python 来帮忙了。
python-docx 库简介
python-docx 是一个可以对 Word 进行读写操作的第三方库,可以读取 Word 内容,可以为 Word 文档添加段落、表格、图片、标题,应用段落样式、粗体和斜体、字符样式。
执行如下安装命令即可完成安装:
pip install python-docx
官方文档: https://python-docx.readthedocs.io/
读取 Word
这里我先创建了一个样例,里面有标题、正文、表格:
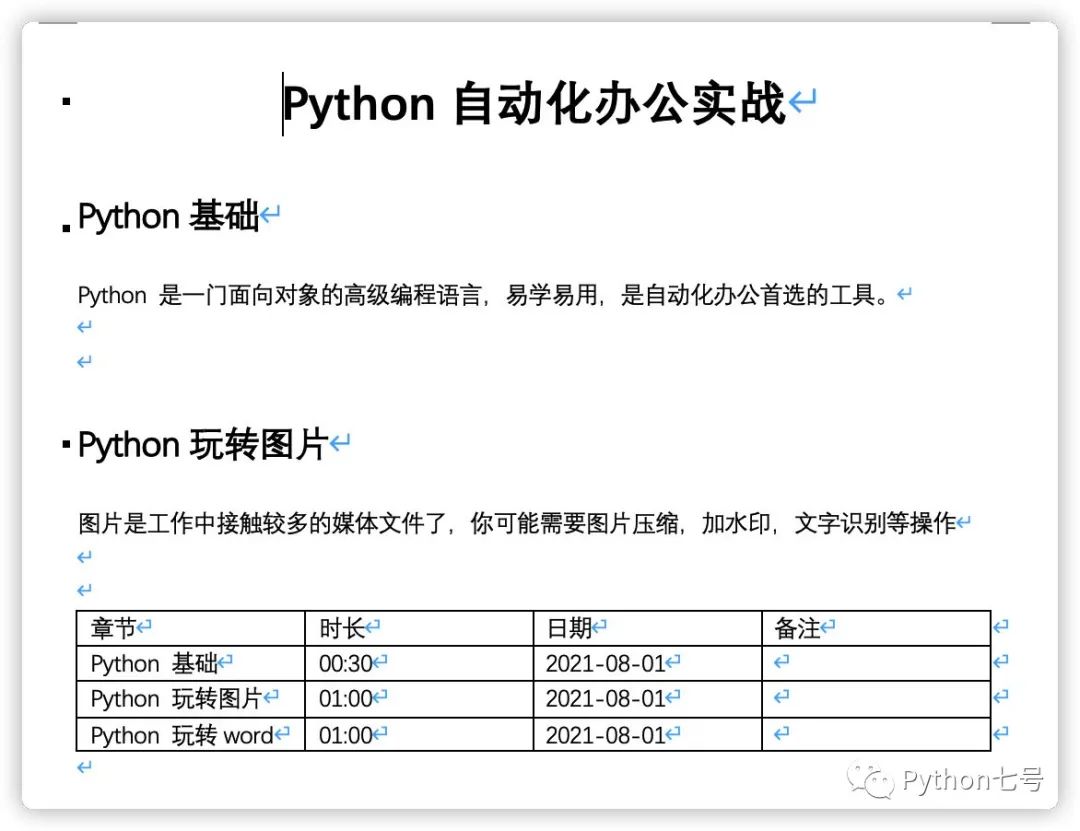
读取 Word 内容的代码如下:
from docx import Document
def view_docs(docx_file):
# 打开文档1
doc = Document(docx_file)
# 读取每段内容
pl = [ paragraph.text for paragraph in doc.paragraphs]
# 输出读取到的内容
for i in pl:
print(i)
def view_docs_table(docx_file):
# 打开文档1
doc = Document(docx_file)
# 读取每段内容
tables = [table for table in doc.tables]
for table in tables:
for row in table.rows:
for cell in row.cells:
print(cell.text, end=' ')
print()
print('\n')
if __name__ == '__main__':
view_docs("Python自动化办公实战课.docx")
view_docs_table("Python自动化办公实战课.docx")
运行结果如下:

写入 Word
现在,用 Python 创建一个和刚才一样的 Word 文档:
from docx import Document
from docx.shared import Pt, RGBColor
from docx.oxml.ns import qn
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.table import _Cell
from docx.oxml import OxmlElement
def set_cell_border(cell: _Cell, **kwargs):
"""
Set cell`s border
Usage:
set_cell_border(
cell,
top={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
bottom={"sz": 12, "color": "#00FF00", "val": "single"},
start={"sz": 24, "val": "dashed", "shadow": "true"},
end={"sz": 12, "val": "dashed"},
)
"""
tc = cell._tc
tcPr = tc.get_or_add_tcPr()
# check for tag existnace, if none found, then create one
tcBorders = tcPr.first_child_found_in("w:tcBorders")
if tcBorders is None:
tcBorders = OxmlElement('w:tcBorders')
tcPr.append(tcBorders)
# list over all available tags
for edge in ('start', 'top', 'end', 'bottom', 'insideH', 'insideV'):
edge_data = kwargs.get(edge)
if edge_data:
tag = 'w:{}'.format(edge)
# check for tag existnace, if none found, then create one
element = tcBorders.find(qn(tag))
if element is None:
element = OxmlElement(tag)
tcBorders.append(element)
# looks like order of attributes is important
for key in ["sz", "val", "color", "space", "shadow"]:
if key in edge_data:
element.set(qn('w:{}'.format(key)), str(edge_data[key]))
document = Document()
document.styles['Normal'].font.name = u'宋体'
document.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
##标题
def add_header(text, level, align='center'):
title_ = document.add_heading(level=level)
if align == 'center':
title_.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER # 标题居中
elif align == 'right':
title_.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT # 标题居中
title_run = title_.add_run(text) # 添加标题内容
# title_run.font.size = Pt(24) # 设置标题字体大小
title_run.font.name = 'Times New Roman' # 设置标题西文字体
title_run.font.color.rgb = RGBColor(0, 0, 0) # 字体颜色
title_run.element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑') # 设置标题中文字体
add_header(text='Python自动化办公实战', level=1)
add_header(text='Python基础', level=2, align='left')
document.add_paragraph('Python 是一门面向对象的高级编程语言,易学易用,是自动化办公首选的工具。')
add_header('Python玩转图片', level=2, align='left')
document.add_paragraph('图片是工作中接触较多的媒体文件了,你可能需要图片压缩,加水印,文字识别等操作')
records = (
('Python 基础', '00:30', '2021-08-01', ''),
('Python 玩转图片', '01:00', '2021-08-01', ''),
('Python 玩转 Word', '01:00', '2021-08-01', ''),
)
table = document.add_table(rows=1, cols=4)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '章节'
hdr_cells[1].text = '时长'
hdr_cells[2].text = '日期'
hdr_cells[3].text = '备注'
for cell in hdr_cells:
set_cell_border(cell,
top={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
bottom={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
start={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
end={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
)
for chapter, time, date, note in records:
row_cells = table.add_row().cells
row_cells[0].text = chapter
row_cells[1].text = time
row_cells[2].text = date
row_cells[3].text = note
for cell in row_cells:
set_cell_border(cell,
top={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
bottom={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
start={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
end={"sz": 12, "val": "single", "color": "#FF0000", "space": "0"},
)
document.save('Python自动化办公实战.docx')
其中,为表格添加边框的代码由于比较复杂,单独做为一个函数来调用。
生成的 Word 文档如下所示,其中表格边框的颜色,标题的颜色,字体大小,样式都是可以设置的:
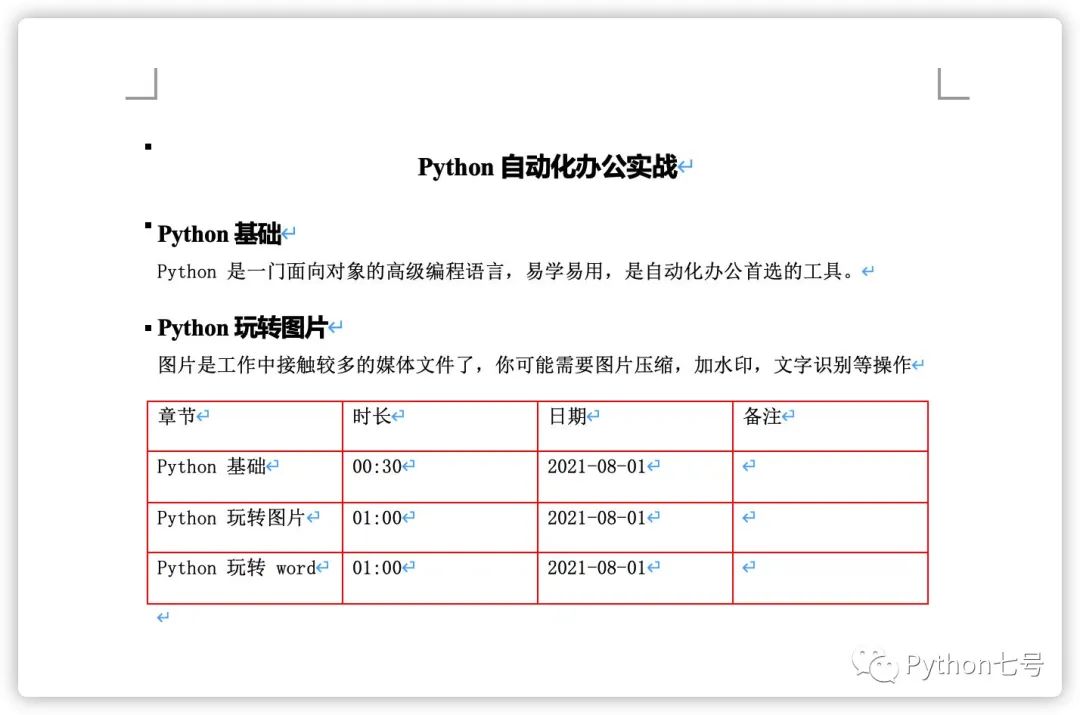
其他操作
添加分页符:
document.add_page_break()
添加图片:
document.add_picture('monty-truth.png', width=Inches(1.25))
设置表格的列宽和行高
''' 设置列宽 可以设置每个单元格的宽,同列单元格宽度相同,如果定义了不同的宽度将以最大值准 ''' table.cell(0,0).width=Cm(10) #设置行高 table.rows[0].height=Cm(2)
表格字体的设定:
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT #设置整个表格字体属性 table.style.font.size=Pt(18) table.style.font.color.rgb=RGBColor(255, 0, 0) table.style.paragraph_format.alignment=WD_PARAGRAPH_ALIGNMENT.CENTER
合并单元格
cell_1=table.cell(1, 0) cell_2=table.cell(2, 1) cell_1.merge(cell_2)
修改文档字体:
from docx import Document
from docx.shared import Pt #设置像素、缩进等
from docx.shared import RGBColor #设置字体颜色
from docx.oxml.ns import qn
doc = Document("xxx.docx")
for paragraph in doc.paragraphs:
for run in paragraph.runs:
run.font.bold = True
run.font.italic = True
run.font.underline = True
run.font.strike = True
run.font.shadow = True
run.font.size = Pt(18)
run.font.color.rgb = RGBColor(255,0,255)
run.font.name = "黑体"
# 设置像黑体这样的中文字体,必须添加下面 2 行代码
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"),"黑体")
doc.save("xxx.docx")
行间距调整:
paragraph.paragraph_format.line_spacing = 5.0
段前与段后间距调整:
#段前 paragraph.paragraph_format.space_before = Pt(12) #段后 paragraph.paragraph_format.space_after = Pt(10)
Word 转 pdf
只需要两行代码就可以将 Word 转 pdf,这里使用的是三方库 docx2pdf 使用前先 pip install docx2pdf。
具体代码如下所示:
from docx2pdf import convert
convert("Python自动化办公实战.docx", "Python自动化办公实战.docx.pdf")
如果要对某个目录下的 Word 批量转换为 pdf,可以这样:
from docx2pdf import convert
convert("目录路径/")
批量转换为 pdf 时是否非常方便?
知道了这些小操作,就可以组装大操作,比如后面可以用 Python 将 Word 转换为 pdf 后作为附件发送邮件给其他人。
最后的话
本文分享了一种读写 Word 的方式,在日常工作中如果是重复性的 Word 操作,可考虑 Python 自动化,有问题请留言交流。阅读原文可以查看 gitee 上的代码。
以上就是Python办公自动化解决world批量转换的详细内容,更多关于Python办公自动化的资料请关注我们其它相关文章!
相关推荐
-
使用Python 自动生成 Word 文档的教程
当然要用第三方库啦 :) 使用以下命令安装: pip install python-docx 使用该库的基本步骤为: 1.建立一个文档对象(可自动使用默认模板建立,也可以使用已有文件). 2.设置文档的格式(默认字体.页面边距等). 3.在文档对象中加入段落文本.表格.图像等,并指定其样式. 4.保存文档. 注:本库仅支持生成Word2007以后版本的文档类型,即扩展名为.docx 的. 下面分步介绍其基本使用方法: 步骤一: from docx import Document doc = Do
-

使用Python自动化Microsoft Excel和Word的操作方法
将Excel与Word集成,无缝生成自动报告 毫无疑问,微软的Excel和Word是公司和非公司领域使用最广泛的两款软件.它们实际上是"工作"的同义词.通常情况下,每一周我们都会将两者结合起来,并以某种方式发挥它们的优点.虽然一般的日常用途不会要求自动化,但有时自动化可能是必需的.也就是说,当您有大量的图表.图形.表格和报告要生成时,如果您选择手动方式,它可能会成为一项极其繁琐的工作.其实没必要这样.实际上,有一种方法可以在Python中创建一个管道,您可以将两者无缝集成,在Excel
-
Python word文本自动化操作实现方法解析
之前介绍了一个Python包 openpyxl ,用于处理 Excel :而对于 Word 文本时同样也有对应的 Python库 Python-docx,在日常办公中,如果需要处理多个 word 文本,且操作步骤都是重复单调的,我想这个库就可以帮到你 在了解 Python-docx 常用函数之前,需要知道 在 Python-docx 各命令所对应 word 各部件,下图所示, Document 指的是 word 文档: paragraph 对应段落: run 对应 一句话中的各个字段,样式调整时
-
基于python实现自动化办公学习笔记(CSV、word、Excel、PPT)
1.CSV (1)写csv文件 import csv def writecsv(path,data): with open(path, "w") as f: writer = csv.writer(f) for rowData in data: print("rowData=", rowData) writer.writerow(rowData) path = r"E:\\Python\\py17\\automatictext\\000001.csv&qu
-
Python办公自动化解决world文件批量转换
目录 python-docx 库简介 读取 Word 写入 Word Word 转 pdf 最后的话 只要是简单重复的工作,就想办法用 Python 来帮你解决吧,人生苦短,你需要 Python. Word 是办公软件中使用频率非常高的软件之一了,假如你需要调整 100 个 Word 文档的格式保持统一,或者要把 100 个 Word 全部转换为 pdf,那么你就需要 Python 来帮忙了. python-docx 库简介 python-docx 是一个可以对 Word 进行读写操作的第三方库
-
基于Python实现GeoServer矢量文件批量发布
目录 0. 前言 1. 环境 1.1 基础环境 1.2 谷歌浏览器驱动 2. 基本流程 2.1 初始化 2.2 登录 2.3 新建数据源 2.4 保存数据存储 2.5 发布图层 3. 完整代码 0. 前言 由于矢量图层文件较多,手动发布费时费力,python支持的关于geoserver包(geoserver-restconfig)又由于年久失修,无法在较新的geoserver版本中正常使用. 查阅了很多资料,参考了下面这篇博客,我简单写了一个自动化发布矢量文件的代码. 基本流程:获取指定文件夹下
-
Python办公自动化PPT批量转换操作
目录 python-pptx 模块的安装 读取 PPT 写入 PPT 添加一张幻灯片 为幻灯片添加内容 获取幻灯片中的形状: 添加自动形状 占位符 访问占位符 将内容插入占位符 如果要插入表格: 如果要插入图表: PPT 转 Pdf 最后的话 如果你有一堆 PPT 要做,他们的格式是一样的,只是填充的内容不一样,那你就可以使用 Python 来减轻你的负担. PPT 分为内容和格式,用 Python 操作 PPT,就是利用 Python 对 PPT 的内容进行获取和填充,修改 PPT 的格式并不
-
Python办公自动化Word转Excel文件批量处理
目录 前言 首先使用Python将Word文件导入 row和cell解析所需内容 内层解析循环 前言 大家好,今天有一个公务员的小伙伴委托我给他帮个忙,大概是有这样一份Word(由于涉及文件私密所以文中的具体内容已做修改) 一共有近2600条类似格式的表格细栏,每个栏目包括的信息有: 日期 发文单位 文号 标题 签收栏 需要提取其中加粗的这三项内容到Excel表格中存储,表格样式如下: 也就是需要将收文时间.文件标题.文号填到指定位置,同时需要将时间修改为标准格式,如果是完全手动复制和修改时间,
-
Python办公自动化批量处理文件实现示例
目录 引言 需求分析 Python实现 结束语 引言 要说在工作中最让人头疼的就是用同样的方式处理一堆文件夹中文件,这并不难,但就是繁.所以在遇到机械式的操作时一定要记得使用Python来合理偷懒!今天我将以处理微博热搜数据来示例如何使用Python批量处理文件夹中的文件,主要将涉及: Python批量读取不同文件夹() Pandas数据处理() Python操作Markdown文件() 需求分析 首先来说明一下需要完成的任务,下面是我们的文件夹结构 因为微博历史热搜是没有办法去爬的,所以只能写
-
Python实现批量转换文件编码的方法
本文实例讲述了Python实现批量转换文件编码的方法.分享给大家供大家参考.具体如下: 这里将某个目录下的所有文件从一种编码转换为另一种编码,然后保存 import os import shutil def match(config,fullpath,type): flag=False if type == 'exclude': for item in config['src']['exclude']: if fullpath.startswith(config['src']['path']+o
-
python实现文件批量编码转换及注意事项
起因:大三做日本交换生期间在修一门C语言图像处理的编程课,在配套书籍的网站上下载了sample,但是由于我用的ubuntu18.04系统默认用utf-8编码,而文件源码是Shift_JIS编码,因而文档注释是乱码.在不改变系统默认编码的前提下,用python将'.c'和'.h'文件的编码转换保存新的文件夹,其余文件原封不动复制. import os abspath = "/home/fanghaoyu/桌面/libraries/" # 新文件夹的路径 try: os.makedirs(
-
使用python批量转换文件编码为UTF-8的实现
由于这两天换了IDE,在导入以前的工程的时候发现了一个大问题,由于以前脑残的我不知道改编码方式,导致出现了大量的GBK,这就很难受,要是一个两个还好说,可是这么多要是一个一个的改我会觉得现在的我比以前还脑残,于是乎,我就想用python批量的修改一下,然后就产生了这篇文章,其中好多不足的地方还请大佬指导 本来一开始的思路还是比较清晰,觉得也比较简单,天真的认为用GBK的方式读取出文件内容,然后UTF8写入就好了,可是在实际的操作中我发现我就是太天真了,出现了大量的问题,比如说: 怎么查看文件的编
-
解决python将xml格式文件转换成txt文件的问题(xml.etree方法)
概述 先来介绍一下xml格式的文件,从数据分析的角度去看xml格式的数据集,具有以下的优点开放性(能在任何平台上读取和处理数据,允许通过一些网络协议交换xml数据).简单性(纯文本,能在不同的系统之间交换数据).结构和内容分离(不同于HTML,数据的显示和数据本身是分开的).可扩展性(派生出其他标记语言) 问题描述 那么我们在进行数据分析的时候,如何运用xml里面的数据呢? 我们就需要将这类文件转化成其他类型的文件. (其实我认为说成提取xml的数据组成新的类型文件比较好一点) 就我个人的观点,
-
利用Python实现快速批量转换HEIC文件
目录 1. 前言 2. 准备 3. 实战 4.最后 1. 前言 最近打算做一批日历给亲朋好友,但是从 iPhone 上导出的照片格式是 HEIC 格式,而商家的在线制作网站不支持这种图片格式 PS:HEIC 是苹果采用的新的默认图片格式,它能在不损失图片画质的情况下,减少图片大小 有很多在线网站支持图片批量转换,但是安全隐私又没法得到保证:如果使用 PS 等软件去一张张转换,浪费时间的同时效率太低 本篇文章将使用 Python 批量实现 HEIC 图片文件的格式转换 2. 准备 首先,我们安装