Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/
(1)环境配置,直接上代码:
# -*- coding: utf-8 -*-
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url = 'http://beijing.8684.cn' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print (start_html.text)
Soup = BeautifulSoup(start_html.text, 'lxml') # 以lxml的方式解析html文档
(2)爬取站点分析
1、北京市公交线路分类方式有3种:

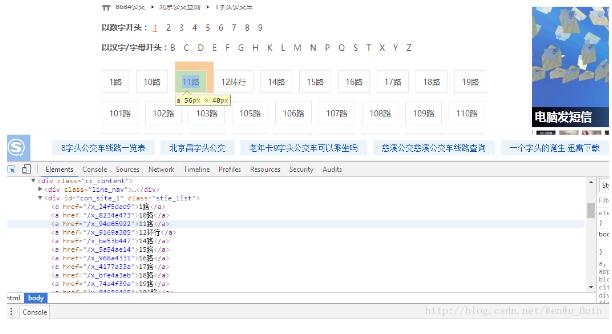
本文通过数字开头来进行爬取,“F12”启动开发者工具,点击“Elements”,点击“1”,可以发现链接保存在<div class="bus_kt_r1">里面,故只需要提取出div里的href即可:
代码:
all_a = Soup.find(‘div',class_='bus_kt_r1').find_all(‘a')
2、接着往下,发现每1路的链接都在<div id="con_site_1" class="site_list"> 的<a>里面,取出里面的herf即为线路网址,其内容即为线路名称,代码:
href = a['href'] #取出a标签的href 属性
html = all_url + href
second_html = requests.get(html,headers=headers)
#print (second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'lxml')
all_a2 = Soup2.find('div',class_='cc_content').find_all('div')[-1].find_all('a') # 既有id又有class的div不知道为啥取不出来,只好迂回取了
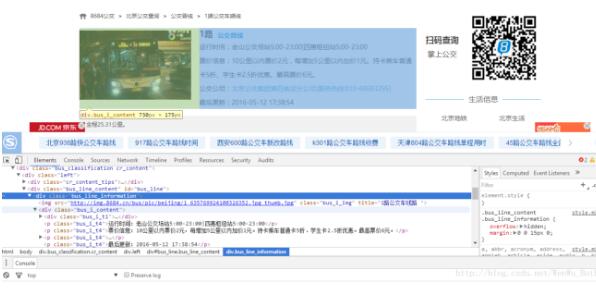
3、打开线路链接,就可以看到具体的站点信息了,打开页面分析文档结构后发现:线路的基本信息存放在<div class="bus_i_content">里面,而公交站点信息则存放在<div class="bus_line_top">及<div class="bus_line_site">里面,提取代码:
title1 = a2.get_text() #取出a1标签的文本
href1 = a2['href'] #取出a标签的href 属性
#print (title1,href1)
html_bus = all_url + href1 # 构建线路站点url
thrid_html = requests.get(html_bus,headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'lxml')
bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text() # 提取线路名
bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text() # 提取线路属性
bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text() # 运行时间
bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text() # 票价
bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text() # 公交公司
bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text() # 更新时间
bus_label = Soup3.find('div',class_='bus_label')
if bus_label:
bus_length = bus_label.get_text() # 线路里程
else:
bus_length = []
#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)
all_line = Soup3.find_all('div',class_='bus_line_top') # 线路简介
all_site = Soup3.find_all('div',class_='bus_line_site')# 公交站点
line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = [] # 上行线路站点
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num==2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = [] # 下行线路站点
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y,sites_y_list=[],[]
information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
自此,我们就把一条线路的相关信息及上、下行站点信息就都解析出来了。如果想要爬取全市的公交网络站点,只需要加入循环就可以了。
完整代码:
# -*- coding: utf-8 -*-
# Python3.5
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url = 'http://beijing.8684.cn' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print (start_html.text)
Soup = BeautifulSoup(start_html.text, 'lxml')
all_a = Soup.find('div',class_='bus_kt_r1').find_all('a')
Network_list = []
for a in all_a:
href = a['href'] #取出a标签的href 属性
html = all_url + href
second_html = requests.get(html,headers=headers)
#print (second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'lxml')
all_a2 = Soup2.find('div',class_='cc_content').find_all('div')[-1].find_all('a') # 既有id又有class的div不知道为啥取不出来,只好迂回取了
for a2 in all_a2:
title1 = a2.get_text() #取出a1标签的文本
href1 = a2['href'] #取出a标签的href 属性
#print (title1,href1)
html_bus = all_url + href1
thrid_html = requests.get(html_bus,headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'lxml')
bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text()
bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text()
bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text()
bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text()
bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text()
bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text()
bus_label = Soup3.find('div',class_='bus_label')
if bus_label:
bus_length = bus_label.get_text()
else:
bus_length = []
#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)
all_line = Soup3.find_all('div',class_='bus_line_top')
all_site = Soup3.find_all('div',class_='bus_line_site')
line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = []
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num==2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = []
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y,sites_y_list=[],[]
information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
Network_list.append(information)
# 定义保存函数,将运算结果保存为txt文件
def text_save(content,filename,mode='a'):
# Try to save a list variable in txt file.
file = open(filename,mode)
for i in range(len(content)):
file.write(str(content[i])+'\n')
file.close()
# 输出处理后的数据
text_save(Network_list,'Network_bus.txt');
最后输出整个城市的公交网络站点信息,这次就先保存在txt文件里吧,也可以保存到数据库里,比如mysql或者MongoDB里,这里我就不写了,有兴趣的可以试一下,附上程序运行后的结果图:

以上这篇Python爬虫实例_城市公交网络站点数据的爬取方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python爬虫_城市公交、地铁站点和线路数据采集实例
- Python爬虫实例爬取网站搞笑段子
- 使用python爬虫实现网络股票信息爬取的demo
相关推荐
-

使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
Python爬虫实例爬取网站搞笑段子
众所周知,python是写爬虫的利器,今天作者用python写一个小爬虫爬下一个段子网站的众多段子. 目标段子网站为"http://ishuo.cn/",我们先分析其下段子的所在子页的url特点,可以轻易发现发现为"http://ishuo.cn/subject/"+数字, 经过测试发现,该网站的反扒机制薄弱,可以轻易地爬遍其所有站点. 现在利用python的re及urllib库将其所有段子扒下 import sys import re import urllib
-
Python爬虫_城市公交、地铁站点和线路数据采集实例
城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息,包含公交.地铁等数据,解析其数据反馈方式,可以通过Python爬虫采集.闲言少叙,接下来将详细介绍如何使用Python爬虫爬取城市公交.地铁站点和数据. 首先,爬取研究城市的所有公交和地铁线路名称,即XX路,地铁X号线.可以通过图吧公交.公交网.8684.本地宝等网站获取,该类网站提供了按数字和字母划分类别的公交线路名称.Pyth
-
Python爬虫实例_城市公交网络站点数据的爬取方法
爬取的站点:http://beijing.8684.cn/ (1)环境配置,直接上代码: # -*- coding: utf-8 -*- import requests ##导入requests from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup import os headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
-
Python爬虫实例之2021猫眼票房字体加密反爬策略(粗略版)
前言: 猫眼票房页面的字体加密是动态的,每次或者每天加载页面的字体文件都会有所变化,本篇内容针对这种加密方式进行分析 字体加密原理:简单来说就是程序员在设计网站的时候使用了自己设计的字体代码对关键字进行编码,在浏览器加载的时会根据这个字体文件对这些字体进行编码,从而显示出正确的字体. 已知的使用了字体加密的一些网站: 58同城,起点,猫眼,大众点评,启信宝,天眼查,实习僧,汽车之家 本篇内容不过多解释字体文件的映射关系,不了解的请自行查找其他资料. 如若还未入门爬虫,请往这走 简单粗暴入门法--
-
Python爬虫入门教程02之笔趣阁小说爬取
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前文 01.python爬虫入门教程01:豆瓣Top电影爬取 基本开发环境 Python 3.6 Pycharm 相关模块的使用 request sparsel 安装Python并添加到环境变量,pip安装需要的相关模块即可. 单章爬取 一.明确需求 爬取小说内容保存到本地 小说名字 小说章节名字 小说内容 # 第一章小说url地址 url = 'http://www.biquges.co
-
Python爬虫实例_利用百度地图API批量获取城市所有的POI点
上篇关于爬虫的文章,我们讲解了如何运用Python的requests及BeautifuiSoup模块来完成静态网页的爬取,总结过程,网页爬虫本质就两步: 1.设置请求参数(url,headers,cookies,post或get验证等)访问目标站点的服务器: 2.解析服务器返回的文档,提取需要的信息. 而API的工作机制与爬虫的两步类似,但也有些许不同: 1.API一般只需要设置url即可,且请求方式一般为"get"方式 2.API服务器返回的通常是json或xml格式的数据,解析更简
-
python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容是不含推送消息的,这里使用selenium+PhantomJS处理 代码 #! /usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
-
Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成 1)搜索要点 美团美食,地址:北京,搜索关键词:火锅 2)爬取的url https://bj.meituan.com/s/%E7%81%AB%E9%94%85/ 3)说明 url会有自动编码中文功能.所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85. 通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词. 这样我们就可以了解到当前url的构造. 2.分析页面数据来源(F12开发者工具) 开启F12开发
-
python爬虫实例详解
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器.HTML下载器和HTML解析器. 爬虫简单架构 程序入口函数(爬虫调度段) #coding:utf8 import time, datetime from maya_Spider import url_manager, html_downloader, html_parser, html_outputer class Spider_Main(object): #初始化操作 def __init__(se
-
python爬虫实例之获取动漫截图
引言 之前有些无聊(呆在家里实在玩的腻了),然后就去B站看了一些python爬虫视频,没有进行基础的理论学习,也就是直接开始实战,感觉跟背公式一样的进行爬虫,也算行吧,至少还能爬一些东西,hhh.我今天来分享一个我的爬虫代码. 正文 话不多说,直接上完整代码 ps:这个代码有些问题 每次我爬到fate的图片它就给我报错,我只好用个try来跳过了,如果有哪位大佬能帮我找出错误并给与纠正,我将不胜感激 import requests as r import re import os import t