基于python爬虫数据处理(详解)
一、首先理解下面几个函数
设置变量 length()函数 char_length() replace() 函数 max() 函数
1.1、设置变量 set @变量名=值
set @address='中国-山东省-聊城市-莘县'; select @address
1.2 、length()函数 char_length()函数区别
select length('a')
,char_length('a')
,length('中')
,char_length('中')
1.3、 replace() 函数 和length()函数组合
set @address='中国-山东省-聊城市-莘县'; select @address ,replace(@address,'-','') as address_1 ,length(@address) as len_add1 ,length(replace(@address,'-','')) as len_add2 ,length(@address)-length(replace(@address,'-','')) as _count
etl清洗字段时候有明显分割符的如何确定新的数据表增加几个分割出的字段
计算出com_industry中最多有几个 - 符 以便确定增加几个字段 最大值+1 为可以拆分成的字段数 此表为3 因此可以拆分出4个行业字段 也就是4个行业等级
select max(length(com_industry)-length(replace(com_industry,'-',''))) as _max_count from etl1_socom_data
1.4、设置变量 substring_index()字符串截取函数用法
set @address='中国-山东省-聊城市-莘县'; select substring_index(@address,'-',1) as china, substring_index(substring_index(@address,'-',2),'-',-1) as province, substring_index(substring_index(@address,'-',3),'-',-1) as city, substring_index(@address,'-',-1) as district
1.5、条件判断函数 case when
case when then when then else 值 end as 字段名 select case when 89>101 then '大于' else '小于' end as betl1_socom_data
二、kettle转换etl1清洗
首先建表 步骤在视频里
字段索引 没有提 索引算法建议用BTREE算法增强查询效率
2.1.kettle文件名:trans_etl1_socom_data
2.2.包括控件:表输入>>>表输出
2.3.数据流方向:s_socom_data>>>>etl1_socom_data
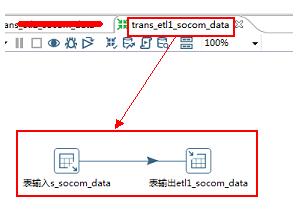
kettle转换1截图
2.4、表输入2.4、SQL脚本 初步清洗com_district和com_industry字段
select a.*, case when com_district like '%业' or com_district like '%织' or com_district like '%育' then null else com_district end as com_district1 ,case when com_district like '%业' or com_district like '%织' or com_district like '%育' then concat(com_district,'-',com_industry) else com_industry end as com_industry_total ,replace(com_addr,'地 址:','') as com_addr1 ,replace(com_phone,'电 话:','') as com_phone1 ,replace(com_fax,'传 真:','') as com_fax1 ,replace(com_mobile,'手机:','') as com_mobile1 ,replace(com_url,'网址:','') as com_url1 ,replace(com_email,'邮箱:','') as com_email1 ,replace(com_contactor,'联系人:','') as com_contactor1 ,replace(com_emploies_nums,'公司人数:','') as com_emploies_nums1 ,replace(com_reg_capital,'注册资金:万','') as com_reg_capital1 ,replace(com_type,'经济类型:','') as com_type1 ,replace(com_product,'公司产品:','') as com_product1 ,replace(com_desc,'公司简介:','') as com_desc1 from s_socom_data as a
2.5、表输出
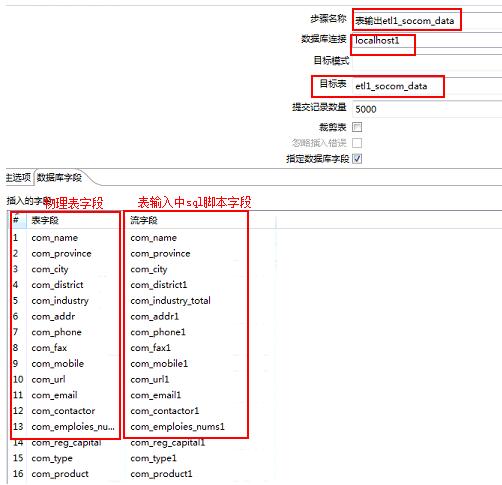
表输出设置注意事项
注意事项:
① 涉及爬虫增量操作 不要勾选裁剪表选项
②数据连接问题 选择表输出中表所在的数据库
③字段映射问题 确保数据流中的字段和物理表的字段数量一致 对应一致
三、kettle转换etl2清洗
首先建表增加了4个字段 演示步骤在视频里
字段索引 没有提 索引算法建议用BTREE算法增强查询效率
主要针对etl1 生成的新的com_industry进行字段拆分 清洗
3.1.kettle文件名:trans_etl2_socom_data
3.2.包括控件:表输入>>>表输出
3.3.数据流方向:etl1_socom_data>>>>etl2_socom_data
注意事项:
① 涉及爬虫增量操作 不要勾选裁剪表选项
②数据连接问题 选择表输出中表所在的数据库
③字段映射问题 确保数据流中的字段和物理表的字段数量一致 对应一致

kettle转换2截图
3.4、SQL脚本 对com_industry进行拆分 完成所有字段清洗 注册资金字段时间关系没有进行细致拆解 调整代码即可
select a.*, case #行业为''的值 置为空 when length(com_industry)=0 then null #其他的取第一个-分隔符之前 else substring_index(com_industry,'-',1) end as com_industry1, case when length(com_industry)-length(replace(com_industry,'-',''))=0 then null #'交通运输、仓储和邮政业-' 这种值 行业2 也置为null when length(com_industry)-length(replace(com_industry,'-',''))=1 and length(substring_index(com_industry,'-',-1))=0 then null when length(com_industry)-length(replace(com_industry,'-',''))=1 then substring_index(com_industry,'-',-1) else substring_index(substring_index(com_industry,'-',2),'-',-1) end as com_industry2, case when length(com_industry)-length(replace(com_industry,'-',''))<=1 then null when length(com_industry)-length(replace(com_industry,'-',''))=2 then substring_index(com_industry,'-',-1) else substring_index(substring_index(com_industry,'-',3),'-',-1) end as com_industry3, case when length(com_industry)-length(replace(com_industry,'-',''))<=2 then null else substring_index(com_industry,'-',-1) end as com_industry4 from etl1_socom_data as a
四、清洗效果质量检查
4.1爬虫数据源数据和网站数据是否相符
如果本身工作是爬虫和数据处理在一起处理,抓取的时候其实已经判断,此步骤可以省略,如果对接上游爬虫同事,这一步首先判断,不然清洗也是无用功,一般都要求爬虫同事存储请求的url便于后面数据处理查看数据质量
4.2计算爬虫数据源和各etl清洗数据表数据量
注:SQL脚本中没有经过聚合过滤 3个表数据量应相等
4.2.1、sql查询 下面表我是在同一数据库中 如果不在同一数据库 from 后面应加上表所在的数据库名称
不推荐数据量大的时候使用
select count(1) from s_socom_data union all select count(1) from etl1_socom_data union all select count(1) from etl2_socom_data
4.2.2 根据 kettle转换执行完毕以后 表输出总量对比
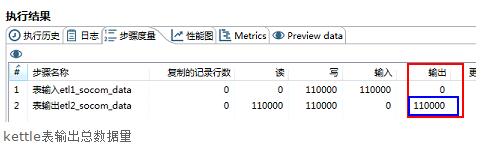
kettle表输出总数据量
4.3查看etl清洗质量
确保前两个步骤已经无误,数据处理负责的etl清洗工作自查开始 针对数据源清洗的字段 写脚本检查 socom网站主要是对地区 和行业进行了清洗 对其他字段做了替换多余字段处理 ,因此采取脚本检查,
找到page_url和网站数据进行核查
where里面这样写便于查看某个字段的清洗情况
select * from etl2_socom_data where com_district is null and length(com_industry)-length(replace(com_industry,'-',''))=3
http://www.socom.cn/company/7320798.html此页面数据和etl2_socom_data表最终清洗数据对比
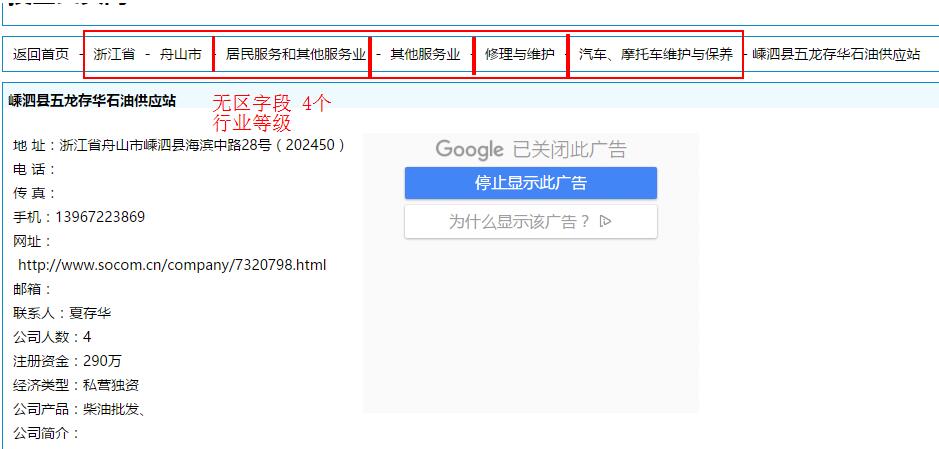
网站页面数据

etl2_socom_data表数据
清洗工作完成。
以上这篇基于python爬虫数据处理(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python数据处理实战(必看篇)
一.运行环境 1.python版本 2.7.13 博客代码均是这个版本 2.系统环境:win7 64位系统 二.需求 对杂乱文本数据进行处理 部分数据截图如下,第一个字段是原字段,后面3个是清洗出的字段,从数据库中聚合字段观察,乍一看数据比较规律,类似(币种 金额 万元)这样,我想着用sql写条件判断,统一转换为'万元人民币' 单位,用sql脚本进行字符串截取即可完成,但是后面发现数据并不规则,条件判断太多清洗质量也不一定,有的前面不是左括号,有的字段里面没有币种,有的数字并不是整数,有的没有万
-
Python 处理数据的实例详解
Python 处理数据的实例详解 最近用python(3.2的版本)写了根据特定规则,处理数据的一个小程序,用到了一些python常用的基础知识,在此总结一下: 1,python读文件 2,python写文件 3,python的流程控制 4,python的for循环 5,python的集合,或字符串里判断是否存在某个元素 6,python的逻辑或,逻辑与 7,python的正则过滤 8,python的字符串忽略空格,和以某个字符串开头和按某个字符拆分成list python的打开文件的模式: 关
-
从零学python系列之数据处理编程实例(二)
在上一节从零学python系列之数据处理编程实例(一)的基础上数据发生了变化,文件中除了学生的成绩外,新增了学生姓名和出生年月的信息,因此将要成变成:分别根据姓名输出每个学生的无重复的前三个最好成绩和出生年月 数据准备:分别建立四个文本文件 james2.txt James Lee,2002-3-14,2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22 julie2.txt Julie Jones,2002-8-17,2.59,2.11
-
从零学python系列之数据处理编程实例(一)
要求:分别以james,julie,mikey,sarah四个学生的名字建立文本文件,分别存储各自的成绩,时间格式都精确为分秒,时间越短成绩越好,分别输出每个学生的无重复的前三个最好成绩,且分秒的分隔符要统一为"." 数据准备:分别建立四个文本文件 james.txt 2-34,3:21,2.34,2.45,3.01,2:01,2:01,3:10,2-22 julie.txt 2.59,2.11,2:11,2:23,3-10,2-23,3:10,3.21,3-21
-
python实现爬虫统计学校BBS男女比例之数据处理(三)
本文主要介绍了数据处理方面的内容,希望大家仔细阅读. 一.数据分析 得到了以下列字符串开头的文本数据,我们需要进行处理 二.回滚 我们需要对httperror的数据进行再处理 因为代码的原因,具体可见本系列文章(二),会导致文本里面同一个id连续出现几次httperror记录: //httperror265001_266001.txt 265002 httperror 265002 httperror 265002 httperror 265002 httperror 265003 httper
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
一个入门级python爬虫教程详解
前言 本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义.组成部分.爬取流程,并讲解示例代码. 基础 爬虫的定义:定向抓取互联网内容(大部分为网页).并进行自动化数据处理的程序.主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料. 今日t条就是一只巨大的"爬虫". 爬虫由URL库.采集器.解析器组成. 流程 如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作. 代码 第一步:写一个采集
-
scrapy处理python爬虫调度详解
学习了简单的知识点,就会想要向有难度的问题挑战,这里必须要夸一夸小伙伴们.不过我们今天不需要做什么程序的测试,只用简单的两个代码对比,小伙伴们就能在其中体会两者的不同和难易程度.scrapy能否适合处理python爬虫调度的问题,小编直接说出答案小伙伴们也不能马上信服,下面就让我们在示例中找寻答案吧. 总的来说,需要使用代码来爬一些数据的大概分为两类人: 非程序员,需要爬一些数据来做毕业设计.市场调研等等,他们可能连 Python 都不是很熟: 程序员,需要设计大规模.分布式.高稳定性的爬虫系统
-
python爬虫实例详解
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器.HTML下载器和HTML解析器. 爬虫简单架构 程序入口函数(爬虫调度段) #coding:utf8 import time, datetime from maya_Spider import url_manager, html_downloader, html_parser, html_outputer class Spider_Main(object): #初始化操作 def __init__(se
-
Python 爬虫多线程详解及实例代码
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
基于Python的身份证验证识别和数据处理详解
根据GB11643-1999公民身份证号码是特征组合码,由十七位数字本体码和一位数字校验码组成,排列顺序从左至右依次为: 六位数字地址码八位数字出生日期码三位数字顺序码一位数字校验码(数字10用罗马X表示) 校验系统: 校验码采用ISO7064:1983,MOD11-2校验码系统(图为校验规则样例) 用身份证号的前17位的每一位号码字符值分别乘上对应的加权因子值,得到的结果求和后对11进行取余,最后的结果放到表2检验码字符值..换算关系表中得出最后的一位身份证号码 代码: # coding=ut
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
python 多进程队列数据处理详解
我就废话不多说了,直接上代码吧! # -*- coding:utf8 -*- import paho.mqtt.client as mqtt from multiprocessing import Process, Queue import time, random, os import camera_person_num MQTTHOST = "172.19.4.4" MQTTPORT = 1883 mqttClient = mqtt.Client() q = Queue() # 连
-
cookies应对python反爬虫知识点详解
在保持合理的数据采集上,使用python爬虫也并不是一件坏事情,因为在信息的交流上加快了流通的频率.今天小编为大家带来了一个稍微复杂一点的应对反爬虫的方法,那就是我们自己构造cookies.在开始正式的构造之前,我们先进行简单的分析如果不构造cookies爬虫时会出现的一些情况,相信这样更能体会出cookies的作用. 网站需要cookies才能正常返回,但是该网站的cookies过期很快,我总不能用浏览器开发者工具获取cookies,然后让程序跑一会儿,每隔几分钟再手动获取cookies,再让
-
Python基于ImageAI实现图像识别详解
目录 背景简介 图像预测 算法引入 目标检测 图像目标检测 视频目标检测 背景简介 ImageAI是一个面向计算机视觉编程的Python库,支持最先进的机器学习算法.主要图像预测,物体检测,视频对象检测与跟踪等多个应用领域.利用ImageAI,开发人员可用很少的代码构建出具有包含深度学习和计算机视觉功能的应用系统. ImageAI目前支持在ImageNet数据集上对多种不同机器算法进行图像预测和训练,ImageNet数据集项目始于2006年,它是一项持续的研究工作,旨在为世界各地的研究人员提供易