一个入门级python爬虫教程详解
前言
本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义、组成部分、爬取流程,并讲解示例代码。
基础
爬虫的定义:定向抓取互联网内容(大部分为网页)、并进行自动化数据处理的程序。主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料。
今日t条就是一只巨大的“爬虫”。
爬虫由URL库、采集器、解析器组成。
流程
如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作。

代码
第一步:写一个采集器
如下是一个比较简单的采集器函数。需要用到requests库。
首先,构造一个http的header,里面有浏览器和操作系统等信息。如果没有这个伪造的header,可能会被目标网站的WAF等防护设备识别为机器代码并干掉。
然后,用requests库的get方法获取url内容。如果http响应代码是200 ok,说明页面访问正常,将该函数返回值设置为文本形式的html代码内容。
如果响应代码不是200 ok,说明页面不能正常访问,将函数返回值设置为特殊字符串或代码。
import requests
def get_page(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
response = requests.get(url, headers= headers)
if response.status_code == 200:
return response.text
else:
return 'GET HTML ERROR !'
第二步:解析器
解析器的作用是对采集器返回的html代码进行过滤筛选,提取需要的内容。
作为一个14年忠实用户,当然要用豆瓣举个栗子 _
我们计划爬取豆瓣排名TOP250电影的8个参数:排名、电影url链接、电影名称、导演、上映年份、国家、影片类型、评分。整理成字典并写入文本文件。
待爬取的页面如下,每个页面包括25部电影,共计10个页面。
在这里,必须要表扬豆瓣的前端工程师们,html标签排版非常工整具有层次,非常便于信息提取。
下面是“肖申克的救赎”所对应的html代码:(需要提取的8个参数用红线标注)
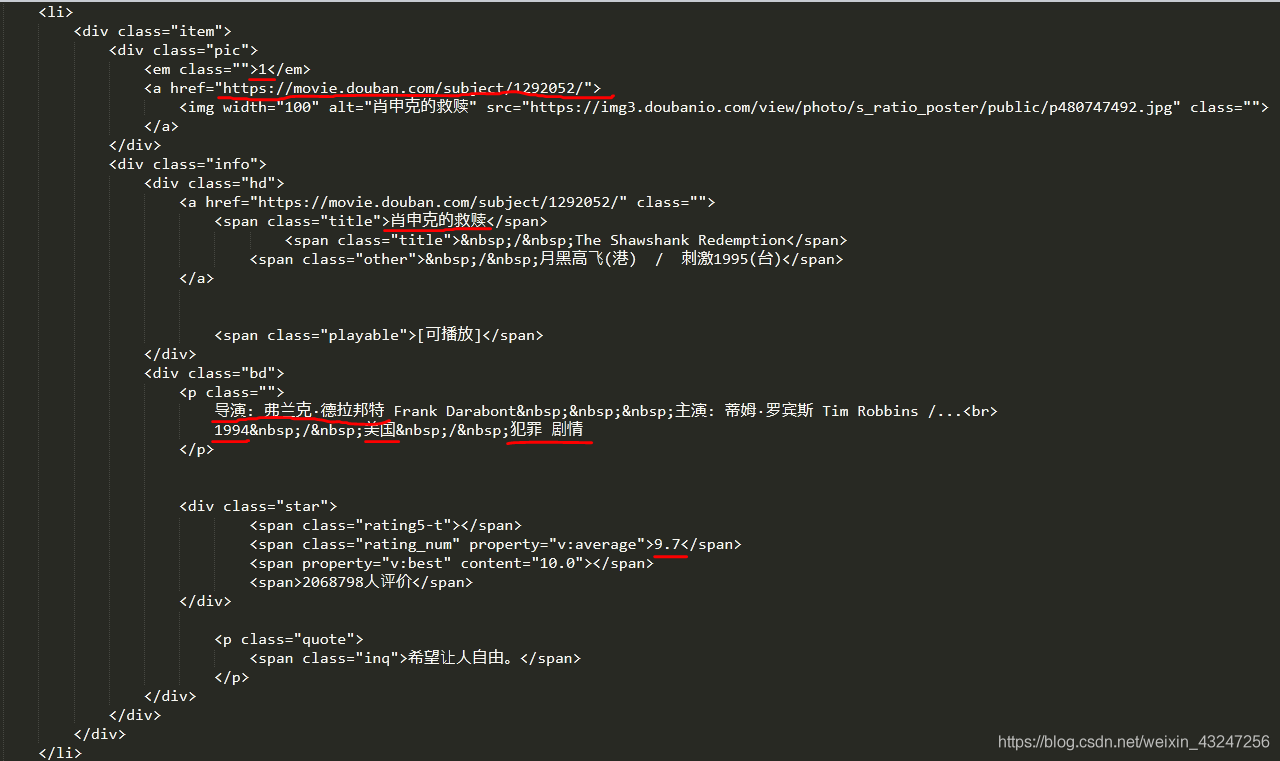
根据上面的html编写解析器函数,提取8个字段。该函数返回值是一个可迭代的序列。
我个人喜欢用re(正则表达式)提取内容。8个(.*?)分别对应需要提取的字段。
import re
def parse_page(html):
pattern = re.compile('<em class="">(.*?)</em>.*?<a href="(.*?)" rel="external nofollow" rel="external nofollow" >.*?<span class="title">(.*?)</span>.*?<div class="bd">.*?<p class="">(.*?) .*?<br>(.*?) / (.*?) / (.*?)</p>.*?<span class="rating_num".*?"v:average">(.*?)</span>' , re.S)
items = re.findall(pattern , html)
for item in items:
yield {
'rank': item[0],
'href': item[1],
'name': item[2],
'director': item[3].strip()[4:],
'year': item[4].strip(),
'country': item[5].strip(),
'style': item[6].strip(),
'score': item[7].strip()
}
提取后的内容如下:

整理成完整的代码:(暂不考虑容错)
import requests
import re
import json
def get_page(url):
#采集器函数
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'}
response = requests.get(url, headers= headers)
if response.status_code == 200:
return response.text
else:
return 'GET HTML ERROR ! '
def parse_page(html):
#解析器函数
pattern = re.compile('<em class="">(.*?)</em>.*?<a href="(.*?)" rel="external nofollow" rel="external nofollow" >.*?<span class="title">(.*?)</span>.*?<div class="bd">.*?<p class="">(.*?) .*?<br>(.*?) / (.*?) / (.*?)</p>.*?<span class="rating_num".*?"v:average">(.*?)</span>' , re.S)
items = re.findall(pattern , html)
for item in items:
yield {
'rank': item[0],
'href': item[1],
'name': item[2],
'director': item[3].strip()[4:],
'year': item[4].strip(),
'country': item[5].strip(),
'style': item[6].strip(),
'score': item[7].strip()
}
def write_to_file(content):
#写入文件函数
with open('result.txt' , 'a' , encoding = 'utf-8') as file:
file.write(json.dumps(content , ensure_ascii = False) + '\n')
if __name__== "__main__":
# 主程序
for i in range(10):
url= 'https://movie.douban.com/top250?start='+ str(i*25)+ '&filter'
for res in parse_page(get_page(url)):
write_to_file(res)
非常简洁,非常符合python简单、高效的特点。
说明:
需要掌握待爬取url的规律,才能利用for循环等操作自动化处理。
前25部影片的url是https://movie.douban.com/top250?start=0&filter,第26-50部影片url是https://movie.douban.com/top250?start=25&filter。规律就在start参数,将start依次设置为0、25、50、75。。。225,就能获取所有页面的链接。parse_page函数的返回值是一个可迭代序列,可以理解为字典的集合。运行完成后,会在程序同目录生成result.txt文件。内容如下:

到此这篇关于一个入门级python爬虫教程详解的文章就介绍到这了,更多相关python爬虫入门教程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫天气预报实例详解(小白入门)
本文研究的主要是Python爬虫天气预报的相关内容,具体介绍如下. 这次要爬的站点是这个:http://www.weather.com.cn/forecast/ 要求是把你所在城市过去一年的历史数据爬出来. 分析网站 首先来到目标数据的网页 http://www.weather.com.cn/weather40d/101280701.shtml 我们可以看到,我们需要的天气数据都是放在图表上的,在切换月份的时候,发现只有部分页面刷新了,就是天气数据的那块,而URL没有变化. 这是因为网页前端使用
-
Python的爬虫程序编写框架Scrapy入门学习教程
1. Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 Scrapy 使用了 Twisted异步网络库来处理网络通讯.整体架构大致如下 Scrapy
-
python爬虫入门教程--HTML文本的解析库BeautifulSoup(四)
前言 python爬虫系列文章的第3篇介绍了网络请求库神器 Requests ,请求把数据返回来之后就要提取目标数据,不同的网站返回的内容通常有多种不同的格式,一种是 json 格式,这类数据对开发者来说最友好.另一种 XML 格式的,还有一种最常见格式的是 HTML 文档,今天就来讲讲如何从 HTML 中提取出感兴趣的数据 自己写个 HTML 解析器来解析吗?还是用正则表达式?这些都不是最好的办法,好在,Python 社区在这方便早就有了很成熟的方案,BeautifulSoup 就是这一类问题
-
Python抓取框架Scrapy爬虫入门:页面提取
前言 Scrapy是一个非常好的抓取框架,它不仅提供了一些开箱可用的基础组建,还能够根据自己的需求,进行强大的自定义.本文主要给大家介绍了关于Python抓取框架Scrapy之页面提取的相关内容,分享出来供大家参考学习,下面随着小编来一起学习学习吧. 在开始之前,关于scrapy框架的入门大家可以参考这篇文章:http://www.jb51.net/article/87820.htm 下面创建一个爬虫项目,以图虫网为例抓取图片. 一.内容分析 打开 图虫网,顶部菜单"发现" "
-
python3爬虫之入门基础和正则表达式
前面的python3入门系列基本上也对python入了门,从这章起就开始介绍下python的爬虫教程,拿出来给大家分享:爬虫说的简单,就是去抓取网路的数据进行分析处理:这章主要入门,了解几个爬虫的小测试,以及对爬虫用到的工具介绍,比如集合,队列,正则表达式: 用python抓取指定页面: 代码如下: import urllib.request url= "http://www.baidu.com" data = urllib.request.urlopen(url).read()# d
-
python爬虫神器Pyppeteer入门及使用
前言 提起selenium想必大家都不陌生,作为一款知名的Web自动化测试框架,selenium支持多款主流浏览器,提供了功能丰富的API接口,经常被我们用作爬虫工具来使用.但是selenium的缺点也很明显,比如速度太慢.对版本配置要求严苛,最麻烦是经常要更新对应的驱动. 今天就给大家介绍另一款web自动化测试工具Pyppeteer,虽然支持的浏览器比较单一,但在安装配置的便利性和运行效率方面都要远胜selenium. 01.Pyppeteer简介 介绍Pyppeteer之前先说一下Puppe
-
一个入门级python爬虫教程详解
前言 本文目的:根据本人的习惯与理解,用最简洁的表述,介绍爬虫的定义.组成部分.爬取流程,并讲解示例代码. 基础 爬虫的定义:定向抓取互联网内容(大部分为网页).并进行自动化数据处理的程序.主要用于对松散的海量信息进行收集和结构化处理,为数据分析和挖掘提供原材料. 今日t条就是一只巨大的"爬虫". 爬虫由URL库.采集器.解析器组成. 流程 如果待爬取的url库不为空,采集器会自动爬取相关内容,并将结果给到解析器,解析器提取目标内容后进行写入文件或入库等操作. 代码 第一步:写一个采集
-
windows上安装Anaconda和python的教程详解
一提到数字图像处理编程,可能大多数人就会想到matlab,但matlab也有自身的缺点: 1.不开源,价格贵 2.软件容量大.一般3G以上,高版本甚至达5G以上. 3.只能做研究,不易转化成软件. 因此,我们这里使用Python这个脚本语言来进行数字图像处理. 要使用Python,必须先安装python,一般是2.7版本以上,不管是在windows系统,还是Linux系统,安装都是非常简单的. 要使用python进行各种开发和科学计算,还需要安装对应的包.这和matlab非常相似,只是matla
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
scrapy处理python爬虫调度详解
学习了简单的知识点,就会想要向有难度的问题挑战,这里必须要夸一夸小伙伴们.不过我们今天不需要做什么程序的测试,只用简单的两个代码对比,小伙伴们就能在其中体会两者的不同和难易程度.scrapy能否适合处理python爬虫调度的问题,小编直接说出答案小伙伴们也不能马上信服,下面就让我们在示例中找寻答案吧. 总的来说,需要使用代码来爬一些数据的大概分为两类人: 非程序员,需要爬一些数据来做毕业设计.市场调研等等,他们可能连 Python 都不是很熟: 程序员,需要设计大规模.分布式.高稳定性的爬虫系统
-
python爬虫实例详解
本篇博文主要讲解Python爬虫实例,重点包括爬虫技术架构,组成爬虫的关键模块:URL管理器.HTML下载器和HTML解析器. 爬虫简单架构 程序入口函数(爬虫调度段) #coding:utf8 import time, datetime from maya_Spider import url_manager, html_downloader, html_parser, html_outputer class Spider_Main(object): #初始化操作 def __init__(se
-
Python 爬虫多线程详解及实例代码
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
使用Atom支持基于Jupyter的Python开教程详解
有关于使用Atom进行Python开发的网上资料比较少,最近发现使用Atom结合Hydrogen插件进行Python开发,尤其是数据挖掘相关的工作,整体体验要好于Vscode,Vscode虽然说也有连接Jupyter的工具,但是交互式的开发Hydrogen体验更好. 这里放了个动图来展示一下Hydrogen的强大 插件安装 Python Hydrogen atom-ide-ui ide-python 这里要注意,本地的pip需要 安装 python-language-server[all],在i
-
Python爬虫库urllib的使用教程详解
目录 Python urllib库 urllib.request模块 urlopen函数 Request 类 urllib.error模块 URLError 示例 HTTPError示例 URLError和HTTPError混合使用 urllib.parse模块 urlparse() urlunparse() urlsplit() urljoin() URL 转码 编码quote(string) 编码urlencode() 解码 unquote(string) urllib.robotparse
-
Python中Selenium库使用教程详解
selenium介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 中文参考文档 官网 环境安装 下载安装selenium pip install selenium -i https://mirrors.aliyun.com/pypi/simple/ 谷歌浏览器驱动程序下载地址:
-
python MySQLdb使用教程详解
本文主要内容python MySQLdb数据库批量插入insert,更新update的: 1.python MySQLdb的使用,写了一个基类让其他的sqldb继承这样比较方便,数据库的ip, port等信息使用json配置文件 2.常见的查找,批量插入更新 下面贴出基类代码: # _*_ coding:utf-8 _*_ import MySQLdb import json import codecs # 这个自己改一下啊 from utils.JsonUtil import get_json