用python修改excel表某一列内容的操作方法
想想你在一家公司里做表格,现在有一个下面这样的excel表摆在你面前,这是一个员工每个月工资的表,

现在假设,你要做的事情,是填充好后面几个月每个员工的编号,并且给员工随机生成一个2000到50000之间的随机数作为该月的工资,能拿多少全靠天意,你为了锻炼自己的python能力决定写一个相关的代码:
1 库引入
首先要引入库函数,要修改excel内容首先需要有openpyxl这个库,要生成随机数就要有random这个库
import openpyxl import random
2 提取cell
我们首先提取编号:
编号是第B列
workbook=openpyxl.load_workbook('工资.xlsx')
table = workbook['Sheet1']
print(table['B'])

3 提取List
但此时我们发现提取出的是cell格式的数据而不是我们常见的list格式,我们可以通过以下方式获得list格式:
def cell2List(CELL):
LIST=[]
for cell in CELL:
LIST.append(cell.value)
return LIST
IDList=cell2List(table['B'])
print(IDList)

4 修改List数据
接下来我们要找到 ‘工作编号' 这几个字的位置
def get_location_in_list(x, target):
step = -1
items = list()
for i in range(x.count(target)):
y = x[step + 1:].index(target)
step = step + y + 1
items.append(step)
return items
IDPos=get_location_in_list(IDList, '工作编号')
print(IDPos)

接下来我们要将最前面的员工名称复制到后面,假设我们已经知道有5个人,且知道小标题占两个格子(‘工作编号' 这几个字后面跟着' ')
那么编写如下代码:
staffNum=5
for i in range(0,len(IDPos)):
IDList[IDPos[i]+1:IDPos[i]+2+staffNum]=IDList[IDPos[0]+1:IDPos[0]+2+staffNum]
print(IDList)

5 修改cell值
这时候我们只需要将只赋回cell即可:
tempi=0
for cell in table['B']:
cell.value=IDList[tempi]
tempi=tempi+1
这时候却发现如下报错:

这时因为我们有的格子是合并起来的
只需要将代码改成如下形式即可:
tempi=0
for cell in table['B']:
try:
cell.value=IDList[tempi]
except:
print('')
tempi=tempi+1
6 存储回原EXCEL或新EXCEL
主要靠更改后面参数,例如我想新存一个result.xlsx
workbook.save(filename = "result.xlsx")
7 其他格式修正(居左为例)
假如你发现,此时存储结果编号局中了:
我想将其居左,只需将前面代码修改为:
tempi=0
for cell in table['B']:
try:
cell.value=IDList[tempi]
cell.alignment = openpyxl.styles.Alignment(horizontal='left', vertical='center')
except:
print('')
tempi=tempi+1
8 随机生成工资
与前面类似,较为简单,建议看完整代码自己领悟嗷
9 完整代码
import openpyxl
import random
def cell2List(CELL):
LIST=[]
for cell in CELL:
LIST.append(cell.value)
return LIST
def get_location_in_list(x, target):
step = -1
items = list()
for i in range(x.count(target)):
y = x[step + 1:].index(target)
step = step + y + 1
items.append(step)
return items
workbook=openpyxl.load_workbook('工资.xlsx')
table = workbook['Sheet1']
IDList=cell2List(table['B'])
salaryList=cell2List(table['C'])
IDPos=get_location_in_list(IDList, '工作编号')
staffNum=5
for i in range(0,len(IDPos)):
IDList[IDPos[i]+1:IDPos[i]+2+staffNum]=IDList[IDPos[0]+1:IDPos[0]+2+staffNum]
for j in range(IDPos[i]+1,IDPos[i]+2+staffNum):
salaryList[j]=1
# tempi=0
# for cell in table['B']:
# cell.value=IDList[tempi]
# tempi=tempi+1
tempi=0
for cell in table['B']:
try:
cell.value=IDList[tempi]
cell.alignment = openpyxl.styles.Alignment(horizontal='left', vertical='center')
except:
print('')
tempi=tempi+1
tempi=0
for cell in table['C']:
try:
if salaryList[tempi]==1:
cell.value=random.randint(2000,50000)
except:
print('')
tempi=tempi+1
workbook.save(filename = "result.xlsx")
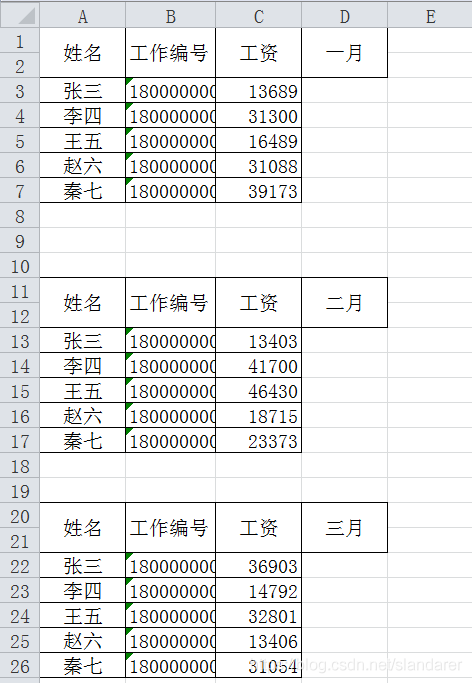
效果:
以上就是用python修改excel表某一列内容的详细内容,更多关于python修改excel的资料请关注我们其它相关文章!
相关推荐
-

Python实现提取XML内容并保存到Excel中的方法
本文实例讲述了Python实现提取XML内容并保存到Excel中的方法.分享给大家供大家参考,具体如下: 最近做一个项目是解析XML文件,提取其中的chatid和lt.timestamp等信息,存到excel里. 1.解析xml,提取数据 使用python自带的xml.dom中的minidom(也可以用lxml) xml文件如下: minidom.parse()#解析文件,返回DOM对象 _get_documentElement()DOM是树形结构,获得了树形结构的根节点 getElements
-
Python读取txt内容写入xls格式excel中的方法
由于xlwt目前只支持xls格式,至于xlsx格式,后面会继续更新 import xlwt import codecs def Txt_to_Excel(inputTxt,sheetName,start_row,start_col,outputExcel): fr = codecs.open(inputTxt,'r') wb = xlwt.Workbook(encoding = 'utf-8') ws = wb.add_sheet(sheetName) line_number = 0#记录有多少
-
python爬取内容存入Excel实例
最近老师布置了个作业,爬取豆瓣top250的电影信息.按照套路,自然是先去看看源代码了,一看,基本的信息竟然都有,心想这可省事多了.简单分析了下源代码,标记出所需信息的所在标签,ok,开始干活! 鉴于正则表达式的资料已经看了不少,所以本次除了beautifulsoup外,还有些re的使用,当然,比较简单.而爬到信息后,以往一般是存到txt文件,或者数据库中,老是重样的操作,难免有些'厌倦'.心想,干嘛不存到Excel表呢?对啊,可以存到Excel表. 环境准备:pip install openp
-
python对Excel按条件进行内容补充(推荐)
关于xlrd/xlwt和openpyxl的差别 两者都是对于excel文件的操作插件,两者的主要区别在于写入操作, 其中xlwt针对Ecxec2007之前的版本,即.xls文件,其要求单个sheet不超过65535行, 而openpyxl则主要针对Excel2007之后的版本(.xlsx),它对文件大小没有限制. 另外还有区别就是二者在读写速度上的差异,xlrd/xlwt在读写方面的速度都要优于openpyxl,但xlwt无法生成xlsx openpyxl的用法 官方文档 先了解下Workshe
-
python批量将excel内容进行翻译写入功能
由于小编初来乍到,有很多地方不是很到位,还请见谅,但是很实用的哦! 1.首先是需要进行文件的读写操作,需要获取文件路径,方式使用os.listdir(路径)进行批量查找文件. file_path = '/home/xx/xx/xx' # ret 返回一个列表 ret = list_dir = os.listdir(file_path) # 遍历列表,获取需要的结尾文件(只考虑获取文件,不考虑执行效率) for i in ret : if i.endswith('xlsx'): # 执行的逻辑 2
-
如何基于python操作excel并获取内容
这篇文章主要介绍了如何基于python操作excel并获取内容,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景:从excel表中获取请求url.请求数据.请求类型.预期结果 因此,需要学会如何使用python从excel获取这些信息 #coding=utf-8 import xlrd #创建对象时,获取对应excel 表格 #读取Excel行数 #获取单元格内容 class OperationExcel: def __init__(self
-
用python修改excel表某一列内容的操作方法
想想你在一家公司里做表格,现在有一个下面这样的excel表摆在你面前,这是一个员工每个月工资的表, 现在假设,你要做的事情,是填充好后面几个月每个员工的编号,并且给员工随机生成一个2000到50000之间的随机数作为该月的工资,能拿多少全靠天意,你为了锻炼自己的python能力决定写一个相关的代码: 1 库引入 首先要引入库函数,要修改excel内容首先需要有openpyxl这个库,要生成随机数就要有random这个库 import openpyxl import random 2 提取cell
-
Python修改Excel数据的实例代码
在前面的文章中介绍了如何用Python读写Excel数据,今天再介绍一下如何用Python修改Excel数据.需要用到xlutils模块.下载地址为https://pypi.python.org/pypi/xlutils.下载后执行python setup.py install命令进行安装即可.具体使用代码如下: 复制代码 代码如下: #-*-coding:utf-8-*-from xlutils.copy import copy # http://pypi.python.org/pypi
-
Python合并Excel表(多sheet)的实现
使用xlrd模块和xlwt模块 解题思想:xlwt模块是非追加写.xls的模块,所以要借助for循环和列表,来一次性写入,这样就没有追加与非追加的说法. 而合并Excel表,把每个Excel表当做行,即行合并,换一种想法,把Excel表中的标签当做列,可进行列合并,即合并不同文件中相同标签组成的不同标签,可以先合并不同文件中相同的标签,不同文件的相同标签组成一个列表,后合并前面组成的不同的标签,即可得到所有Excel文件的内容. 源码如下: #导入xlrd和xlwt模块 #xlrd模块是读取.x
-
利用Python读取Excel表内容的详细过程
目录 用python读取excel表中的数据 这里再多说一下,np.hstack()函数和 np.vstack()函数: 总结 用python读取excel表中的数据 假如说有如下一张存储了数据的excel表,其中x1-x6是特征,y_label是特征对应的类别标签.我们想要使用python对以下数据进行数据分析,那么第一步就要先把excel表中的数据读取出来才行.这里我们主要使用到了python中的pandas库. 首先确定excel表存放的路径所在,比如我的路径是 ‘E:\relate_co
-
python修改注册表终止360进程实例
本文实例讲述了python修改注册表终止360进程的实现方法.分享给大家供大家参考. 具体实现代码如下: import _winreg import os import shutil #复制自身 shutil.copyfile(K3.exe,c:WINDOWSsystem32K3.exe) #把360启动改为自身 run = _winreg.OpenKey( _winreg.HKEY_LOCAL_MACHINE, "SOFTWAREMicrosoftWindowsCurrentVersionRu
-
Python修改文件往指定行插入内容的实例
需求:批量修改py文件中的类属性,为类增加一个core = True新的属性 原py文件如下 a.py class A(): description = "abc" 现在有一个1.txt文本,内容如下,如果有py文件中的description跟txt文本中的一样,则增加core属性 1.txt description = "abc" description = "123" 实现思路: 1.需要遍历code目录下的所有py文件,然后读取所有行数内容
-
使用python采集Excel表中某一格数据
安装并导入模块 打开命令行窗口,输入: pip install -i https://mirrors.aliyun.com/pypi/simple/ openpyxl 导入: from openpyxl import load_workbook 打开表格有两种方式: 1.sheet = workbook.active 打开活跃的/唯一的表格 2.sheet = workbook['sheet1'] 打开表格sheet1 选择某一格也有两种方式: 1.cell = sheet['A1'] 获取A1
-
如何在Python对Excel进行读取
在python自动化中,经常会遇到对数据文件的操作,比如添加多名员工,但是直接将员工数据写在python文件中,不但工作量大,要是以后再次遇到类似批量数据操作还会写在python文件中吗? 应对这一问题,可以将数据写excel文件,针对excel 文件进行操作,完美解决. 本文仅介绍python对excel的操作 安装xlrd 库 xlrd库 官方地址:https://pypi.org/project/xlrd/ pip install xlrd 笔者在安装时使用了 pip3 install x
-
利用Python改正excel表格数据
目录 一.前言 二.代码实现及讲解 1.模块的导入 2.获取“数据原表”中数据 3.获取生产记录更新表中的日期和材料 4.对生产数据更新表中数据的修改 5.最后,调用函数并保存数据 三.效果展示 四.结尾 一.前言 大家好,今天我来介绍我接一个Python单子.我完成这个单子前后不到2小时.首先我接到这个单子的想法是处理Excel表,在两个表之间建立联系,并通过项目需求,修改excel表中的数据.我是运用面向过程写的,将每一步都放在了不同的函数中,下面让我来介绍一下我是怎么通过自己的思路一步一步
-
用python对excel查重
最近媳妇工作上遇到一个重复性劳动,excel表格查重,重复的标记起来,问我能不能写个程序让它自动查重标记 必须安排 第一次正儿八经写python,边上网查资料,边写 终于成功了 在此记录一下 首先安装xlwings库 pip install xlwings 写代码 import xlwings as xw # 输入表名 title = input() # 指定不显示地打开Excel,读取Excel文件 app = xw.App(visible=False, add_book=False) wb