Python中的优先队列(priority queue)和堆(heap)
目录
- 队列和优先队列(Priority Queue)
- 堆(heap)
- 简介
- 初始化构建堆
- 堆的插入(节点上浮)
- 堆的删除(节点下浮)
- 堆的应用
队列和优先队列(Priority Queue)
队列是一种可以完成插入和删除的数据结构。普通队列是先进先出(FIFO), 即先插入的先被删除。
然而在某些时候我们需要按照任务的优先级顺序来决定出队列的顺序,这个时候就需要用到优先级队列了。优先队列是一种可以完成插入和删除最小元素的数据结构
python中有现成的优先队列类可以调用。
代码示例
from queue import Queue # 队列,FIFO from queue import PriorityQueue #优先级队列,优先级高的先输出 ###############队列(Queue)的使用,/python中也可是用列表(list)来实现队列############### q = Queue(maxsize) #构建一个队列对象,maxsize初始化默认为零,此时队列无穷大 q.empty() #判断队列是否为空(取数据之前要判断一下) q.full() #判断队列是否满了 q.put() #向队列存放数据 q.get() #从队列取数据 q.qsize() #获取队列大小,可用于判断是否满/空 ###用法示例: >>> q = Queue(3) >>> for i in range(3): >>> q.put(i) >>> q.full() True >>> while not q.empty(): >>> print(q.get()) 0 1 2 ###############优先队列(PriorityQueue)的使用############### """ 队列的变体,按优先级顺序(最低优先)检索打开的条目。 条目通常是以下格式的元组: 插入格式:q.put((priority number, data)) 特点:priority number 越小,优先级越高 其他的操作和队列相同 """ >>> q = PriorityQueue() >>> q.put((2, "Lisa")) >>> q.put((1, "Lucy")) >>> q.put((0, "Tom")) >>> i = 0 >>> while i < q.qsize(): >>> print(q.get()) (0,"Tom") (1,"Lucy") (2,"Lisa") #可见并没有按照输入的顺序输出的,而是按照优先级顺序输出的 #优先独队列的实质是
堆(heap)
看完上面的示例我们也许会有疑惑,优先队列是如何来实现的了?
----------优先队列的实质是每次插入时按照一定的规则插入,删除时直接找到最小的那个元素弹出即可。插入和弹出最坏情况下的时间复杂度都是O(LogN)
下面我们就来介绍实现优先队列的一种数据结构——堆(heap)。
简介
堆的实质是一个完全二叉树(除最底层外,其余层都是满二叉树,且最底层的节点从左往右顺序排列)。 堆主要分为大顶堆和小顶堆两种
1.大顶堆:每个分支的根节点都大于等于其子节点。(ki >= k2i)and (ki >= k2i+1)
2.小顶堆:每个分支的根节点都小于等于其子节点。(ki <= k2i)and (ki <= k2i+1)
所以堆中的第i个元素的父亲是floor(i/2)(向下取整), 第i个元素的左右孩子分别是2i和2i+1
堆的根节点要从1开始计算,不能从0开始计算。(假如从零开始i=2时其父亲节点为floor(2/2)=1, 显然是错误的)
初始化构建堆
将一个有k个元素的数组构成一个大顶堆或者小顶堆。时间复杂度O(n)$
核心思路:从下往上,从右往左,且每次都从第floor(k/2)个元素开始进行调整依次递减直到根节点
1.从floor(k/2)个元素开始进行调整,调整完毕,则i--;
#调整节点,每次只调整该根节点以下的子树
while i <= k
1.1 找出左右孩子中最大的那个
1.2 该节点和较大的那个子节点比较,
如果父节点较大,break
如果子节点较大,记录子节点的索引,把子节点的值给父节点
1.3 将上面较大的那个字节点作为新的父节点开始一轮循环
循环结束后,将父节点的值放到他应该去的子节点的位置上
例如有如下数组

把其转化成完全二叉树的形式就是
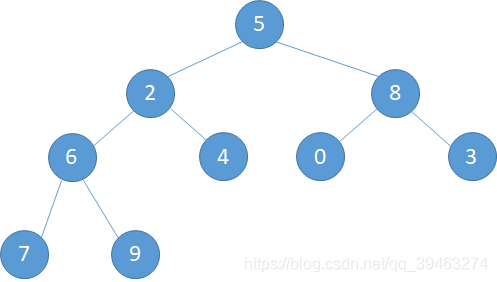
该数组一共有9个元素,所以从i = floor(9/2)=4 个元素开始,第4个元素是6, 其右孩子9最大,将6和9交换完成一次调整.
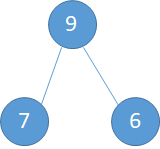
i=3,第三个元素是8,8比左右孩子都大,不用交换

i=2,此时的子树是:第二个元素是2,而此时以2为根节点的子树如下左图。交换过程为: a).2与9交换,此时的根节点就到了2现在的位置 (下中图)。b).2与7交换。 c)交换完成,本次调整完毕
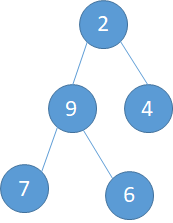
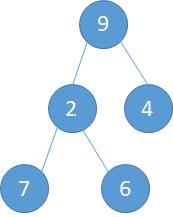
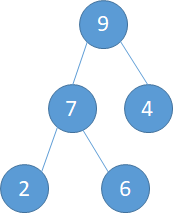
i=1,此时的父节点就是整棵树的根节点,而此时整棵树的状态是下图所示
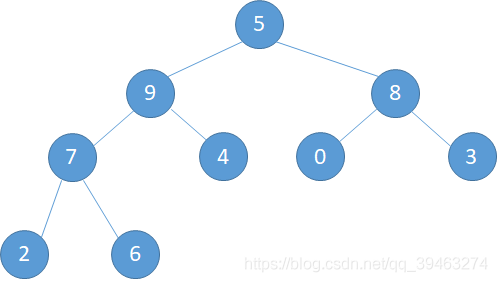
a). 5和9交换,此时5到了9的位置(下左图) b). 5和7交换,5到了7的位置(下中图) c).最后5和6交换,完成调整。
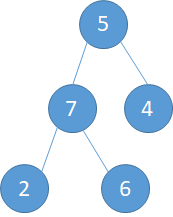

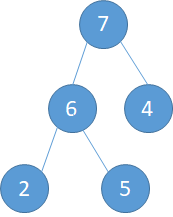
经过以上的floor(k/2)次的调整之后,由一个无序数组初始化构建大顶堆就完成了

堆的插入(节点上浮)
时间复杂度O(log(k+1))
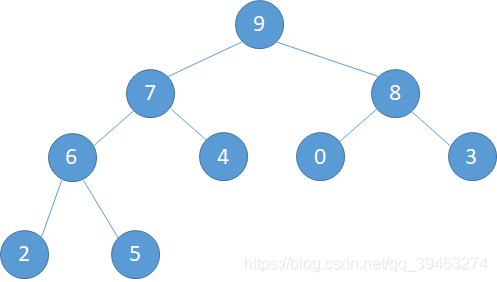
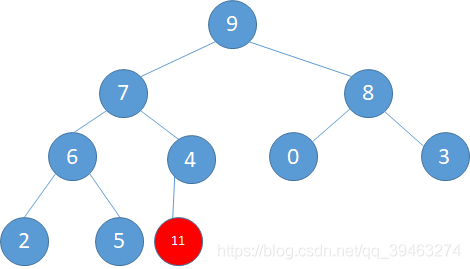
我们之前由一个无序数组构造了一个大顶堆,那么现在我们要插入一个新的元素该怎么办了,如下图,如果直接在最末尾插入,则破坏了堆的结构,所以还需要按进行调整。
调整规则:由于其他子树的顺序都已经调整完毕,所以只需要调整根节点到插入节点所在的子路即可。
如下图所示。(a)将11与4调整,(b)将11与7调整,©再将11与9调整。最后得到调整完毕的结果。
堆的删除(节点下浮)
时间复杂度O(log(k-1))
由于堆是队列结构,只能从堆中删除堆顶的元素。移除堆顶元素之后,之前的完全二叉树就变成来两个子树,次数最方便的做法就是用堆的最后一个节点来填补取走的堆顶元素,并将堆的实际元素个数减1。但是这样做以后又不满足堆的定义了,还是要进行调整。
调整规则:从根节点开始逐层向下调整即可。
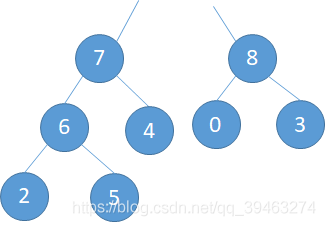
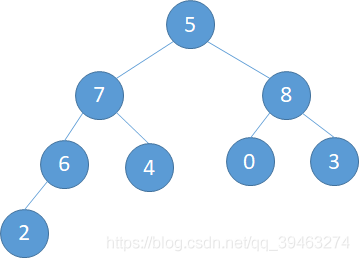
(a).将5与8调换,(b)调整完成,删除完毕

堆的应用
之间讲过的利用堆(python中是小顶堆)来实现优先队列
利用堆求Top k:
假如现在有1亿个数据要求其中前十个最小的元素。最笨方法就是对所有数据进行排序,然后找出前十个最小的,即使使用快排,也需要O(NlogN)的时间复杂度。假如利用大顶堆的话–先利用前10个数据构造一个大顶堆,然后顺序遍历数组与大顶堆顶点比较,假如比大于等于顶点直接删除,否则就删除堆顶点并插入新的节点,最后堆里面的元素就是最小的前是个元素。这样求出来的时间复杂度为Nlog(k)
假如要求前十个最大的元素,那就要使用小顶堆来实现
最后放上python手动实现将数组转化为大顶堆和小顶堆的代码
class Heap:
def __init__(self, _list):
self._list = _list
self.k = len(_list)
def _bigHeapAdjuest(self, j):
temp = self._list[j] #存放当前双亲节点的值,j代表当前节点的位置
i = 2*j #j的左孩子
while i <= self.k:
if i < self.k and self._list[i] < self._list[i+1]: #i==n时由于只有一个子节点,所以没有比较的必要
i += 1
#与双亲比较,如果双亲大则跳过
#如果双亲小,就把大的给双亲
if temp >= self._list[i]:
break #没有必要修整
self._list[j] = self._list[i] #元素交换
j = i #j记录着temp应该去的位置,由于这个位置的节点发生了变动,所以需要再次调整
i *= 2 #接着找该节点的左孩子
self._list[j] = temp
def _smallheapAdjuest(self, j):
temp = self._list[i] #父节点
i = 2*j #左孩子
while i <= self.k:
if i < self.k and self._list[i] > self._list[i+1]: #找最小的那个孩子
i += 1
#构建小顶堆,小于父节点的都要上浮
if self._list[i] >= temp:
break
self._list[j] = self._list[i] #子节点交给父节点
j= i #记录父节点应该去的索引位置
i *= 2
self._list[j] = temp
def heapSort(self):
self._list.insert(0, -1)
s = self.length // 2
#构建大顶堆
for j in range(s, 0, -1):
self._bigHeapAdjuest(j)
#构建小顶堆
for j in range(s, 0, -1):
self._SmallheapAdjuest(j)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python 队列Queue和PriorityQueue解析
目录 Python 队列Queue和PriorityQueue Python的Queue模块 优先级队列PriorityQueue的特点 python 实现一个优先级队列 python 优先队列PriorityQueue 下面是具体的例子 Python 队列Queue和PriorityQueue Python的Queue模块 适用于多线程编程的FIFO实现.它可用于在生产者(producer)和消费者(consumer)之间线程安全(thread-safe)地传递消息或其它数据,因此多个线程可以
-

Python通过队列实现进程间通信详情
目录 一.前言 二.队列简介 三.多进程队列的使用 四.使用队列在进程间通信 一.前言 在多进程中,每个进程之间是什么关系呢?其实每个进程都有自己的地址空间.内存.数据栈以及其他记录其运行状态的辅助数据.下面通过一个例子,验证一下进程之间能否直接共享信息. 定义一个全局变量g_num,分别创建2个子进程对g_num执行不同的操作,并输出操作后的结果. 代码如下: # _*_ coding:utf-8 _*_ from multiprocessing import Process def plus
-
Python常用队列全面详细梳理
目录 一,队列 二,常见队列 1,FIFO队列 2,LIFO队列 3,双向队列 4,优先级队列 5,循环队列 一,队列 和栈一样,队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作.队列是一种操作受限制的线性表,进行插入操作的端称为队尾,进行删除操作的端称为队头.队列中没有元素时,称为空队列. 二,常见队列 1,FIFO队列 基本FIFO队列 先进先出 FIFO即First in First Out,先进先出. 调用queue.
-
Python线程之线程安全的队列Queue
目录 一.什么是队列? 二.队列基操入队/出队/查队列状态 三.Queue是一个线程安全的类 一.什么是队列? 像排队一样,从头到尾排成一排,还可以有人继续往后排队,这就是队列. 这里学委想说的是Queue这个类, 它是queue这个内置模块内的一个类. import queue q = queue.Queue(5) #可以传入参数指定队列大小 queue.Queue()# 不传或者给0或者<0的数字则创建一个无限长度的队列 它提供了很多函数,下面几个函数,我们使用的比较多: get: 获取并移
-
Python数据结构之队列详解
目录 0. 学习目标 1. 队列的基本概念 1.1 队列的基本概念 1.2 队列抽象数据类型 1.3 队列的应用场景 2. 队列的实现 2.1 顺序队列的实现 2.2 链队列的实现 2.3 队列的不同实现对比 3. 队列应用 3.1 顺序队列的应用 3.2 链队列的应用 3.3 利用队列基本操作实现复杂算法 0. 学习目标 栈和队列是在程序设计中常见的数据类型,从数据结构的角度来讲,栈和队列也是线性表,是操作受限的线性表,它们的基本操作是线性表操作的子集,但从数据类型的角度来讲,它们与线性表又有
-
Python实现线程池之线程安全队列
目录 一.线程池组成 二.线程安全队列的实现 三.测试逻辑 3.1.测试阻塞逻辑 3.2.测试读写加锁逻辑 本文实例为大家分享了Python实现线程池之线程安全队列的具体代码,供大家参考,具体内容如下 一.线程池组成 一个完整的线程池由下面几部分组成,线程安全队列.任务对象.线程处理对象.线程池对象.其中一个线程安全的队列是实现线程池和任务队列的基础,本节我们通过threading包中的互斥量threading.Lock()和条件变量threading.Condition()来实现一个简单的.读
-
Python全栈之队列详解
目录 1. lock互斥锁 2. 事件_红绿灯效果 2.1 信号量_semaphore 2.2 事件_红绿灯效果 3. queue进程队列 4. 生产者消费者模型 5. joinablequeue队列使用 6. 总结 1. lock互斥锁 知识点: lock.acquire()# 上锁 lock.release()# 解锁 #同一时间允许一个进程上一把锁 就是Lock 加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲速度却保证了数据
-
Python中的优先队列(priority queue)和堆(heap)
目录 队列和优先队列(Priority Queue) 堆(heap) 简介 初始化构建堆 堆的插入(节点上浮) 堆的删除(节点下浮) 堆的应用 队列和优先队列(Priority Queue) 队列是一种可以完成插入和删除的数据结构.普通队列是先进先出(FIFO), 即先插入的先被删除. 然而在某些时候我们需要按照任务的优先级顺序来决定出队列的顺序,这个时候就需要用到优先级队列了.优先队列是一种可以完成插入和删除最小元素的数据结构 python中有现成的优先队列类可以调用. 代码示例 from q
-
Java优先队列 priority queue
目录 1.优先队列概念 2.二叉堆(Heap) 完全二叉树和满二叉树 堆的重要操作 1.优先队列概念 优先队列(priority queue)是一种特殊的数据结构. 队列中每一个元素都被分配到一个优先权值,出队顺序按照优先权值来划分. 一般有两种出队顺序:高优先权出队或低优先权出队. priority queue至少要有两个最基本的ADT:进队,出队(按照高优先权或低优先权) 产生原因:同样是为了提高数据处理的效率.试想,要实现优先队列对应的功能,若使用链表或者数组,那么要么先排序再插入,要么先
-
python中利用队列asyncio.Queue进行通讯详解
前言 本文主要给大家介绍了关于python用队列asyncio.Queue通讯的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. asyncio.Queue与其它队列是一样的,都是先进先出,它是为协程定义的 例子如下: import asyncio async def consumer(n, q): print('consumer {}: starting'.format(n)) while True: print('consumer {}: waiting for i
-
详解python中asyncio模块
一直对asyncio这个库比较感兴趣,毕竟这是官网也非常推荐的一个实现高并发的一个模块,python也是在python 3.4中引入了协程的概念.也通过这次整理更加深刻理解这个模块的使用 asyncio 是干什么的? 异步网络操作并发协程 python3.0时代,标准库里的异步网络模块:select(非常底层) python3.0时代,第三方异步网络库:Tornado python3.4时代,asyncio:支持TCP,子进程 现在的asyncio,有了很多的模块已经在支持:aiohttp,ai
-
简单谈谈python中的Queue与多进程
最近接触一个项目,要在多个虚拟机中运行任务,参考别人之前项目的代码,采用了多进程来处理,于是上网查了查python中的多进程 一.先说说Queue(队列对象) Queue是python中的标准库,可以直接import 引用,之前学习的时候有听过著名的"先吃先拉"与"后吃先吐",其实就是这里说的队列,队列的构造的时候可以定义它的容量,别吃撑了,吃多了,就会报错,构造的时候不写或者写个小于1的数则表示无限多 import Queue q = Queue.Queue(10
-
python中threading和queue库实现多线程编程
摘要 本文主要介绍了利用python的 threading和queue库实现多线程编程,并封装为一个类,方便读者嵌入自己的业务逻辑.最后以机器学习的一个超参数选择为例进行演示. 多线程实现逻辑封装 实例化该类后,在.object_func函数中加入自己的业务逻辑,再调用.run方法即可. # -*- coding: utf-8 -*- # @Time : 2021/2/4 14:36 # @Author : CyrusMay WJ # @FileName: run.py # @Software:
-
python中heapq堆排算法的实现
目录 一.创建堆 二.访问堆内容 三.获取堆最大或最小值 四.heapq应用 一.创建堆 heapq有两种方式创建堆, 一种是使用一个空列表,然后使用heapq.heappush()函数把值加入堆中,另外一种就是使用heap.heapify(list)转换列表成为堆结构 import heapq # 第一种 """ 函数定义: heapq.heappush(heap, item) - Push the value item onto the heap, maintaining
-
Python中的heapq模块源码详析
起步 这是一个相当实用的内置模块,但是很多人竟然不知道他的存在--笔者也是今天偶然看到的,哎--尽管如此,还是改变不了这个模块好用的事实 heapq 模块实现了适用于Python列表的最小堆排序算法. 堆是一个树状的数据结构,其中的子节点都与父母排序顺序关系.因为堆排序中的树是满二叉树,因此可以用列表来表示树的结构,使得元素 N 的子元素位于 2N + 1 和 2N + 2 的位置(对于从零开始的索引). 本文内容将分为三个部分,第一个部分简单介绍 heapq 模块的使用:第二部分回顾堆排序算法
-
Python数据结构之优先级队列queue用法详解
一.基本用法 Queue类实现了一个基本的先进先出容器.使用put()将元素增加到这个序列的一端,使用get()从另一端删除.具体代码如下所示: import queue q = queue.Queue() for i in range(1, 10): q.put(i) while not q.empty(): print(q.get(), end=" ") 运行之后,效果如下: 这里我们依次添加1到10到队列中,因为先进先出,所以出来的顺序也与添加的顺序相同. 二.LIFO队列 既然
-
Python中的线程操作模块(oncurrent)
目录 GIL锁 1. 创建线程的方式:直接使用Thread 2. 创建线程的方式:继承Thread 二.多线程与多进程 1. pid的比较 2. 开启效率的较量 3. 内存数据的共享问题 三.Thread类的其他方法 1. 代码示例 2. join方法 四.多线程实现socket 五.守护线程 1. 详细解释 2. 守护线程例 六.同步锁 1. 多个线程抢占资源的情况 2.同步锁的引用 3.实例 七.死锁与递归锁 1. 死锁 2. 递归锁(可重入锁)RLock 3.典型问题:科学家吃面 八.线程