Python全栈之队列详解
目录
- 1. lock互斥锁
- 2. 事件_红绿灯效果
- 2.1 信号量_semaphore
- 2.2 事件_红绿灯效果
- 3. queue进程队列
- 4. 生产者消费者模型
- 5. joinablequeue队列使用
- 6. 总结
1. lock互斥锁
知识点:
lock.acquire()# 上锁 lock.release()# 解锁 #同一时间允许一个进程上一把锁 就是Lock 加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲速度却保证了数据安全。 #同一时间允许多个进程上多把锁 就是[信号量Semaphore] 信号量是锁的变形: 实际实现是 计数器 + 锁,同时允许多个进程上锁 # 互斥锁Lock : 互斥锁就是进程的互相排斥,谁先抢到资源,谁就上锁改资源内容,为了保证数据的同步性 # 注意:多个锁一起上,不开锁,会造成死锁.上锁和解锁是一对.
程序实现:
# ### 锁 lock 互斥锁
from multiprocessing import Process,Lock
""" 上锁和解锁是一对, 连续上锁不解锁是死锁 ,只有在解锁的状态下,其他进程才有机会上锁 """
"""
# 创建一把锁
lock = Lock()
# 上锁
lock.acquire()
# lock.acquire() # 连续上锁,造成了死锁现象;
print("我在袅袅炊烟 .. 你在焦急等待 ... 厕所进行时 ... ")
# 解锁
lock.release()
"""
# ### 12306 抢票软件
import json,time,random
# 1.读写数据库当中的票数
def wr_info(sign , dic=None):
if sign == "r":
with open("ticket",mode="r",encoding="utf-8") as fp:
dic = json.load(fp)
return dic
elif sign == "w":
with open("ticket",mode="w",encoding="utf-8") as fp:
json.dump(dic,fp)
# dic = wr_info("w",dic={"count":0})
# print(dic , type(dic) )
# 2.执行抢票的方法
def get_ticket(person):
# 先获取数据库中实际票数
dic = wr_info("r")
# 模拟一下网络延迟
time.sleep(random.uniform(0.1,0.7))
# 判断票数
if dic["count"] > 0:
print("{}抢到票了".format(person))
# 抢到票后,让当前票数减1
dic["count"] -= 1
# 更新数据库中的票数
wr_info("w",dic)
else:
print("{}没有抢到票哦".format(person))
# 3.对抢票和读写票数做一个统一的调用
def main(person,lock):
# 查看剩余票数
dic = wr_info("r")
print("{}查看票数剩余: {}".format(person,dic["count"]))
# 上锁
lock.acquire()
# 开始抢票
get_ticket(person)
# 解锁
lock.release()
if __name__ == "__main__":
lock = Lock()
lst = ["梁新宇","康裕康","张保张","于朝志","薛宇健","韩瑞瑞","假摔先","刘子涛","黎明辉","赵凤勇"]
for i in lst:
p = Process( target=main,args=( i , lock ) )
p.start()
"""
创建进程,开始抢票是异步并发程序
直到开始抢票的时候,变成同步程序,
先抢到锁资源的先执行,后抢到锁资源的后执行;
按照顺序依次执行;是同步程序;
抢票的时候,变成同步程序,好处是可以等到数据修改完成之后,在让下一个人抢,保证数据不乱。
如果不上锁的话,只剩一张票的时候,那么所有的人都能抢到票,因为程序执行的速度太快,所以接近同步进程,导致数据也不对。
"""
ticket文件
{"count": 0}
2. 事件_红绿灯效果
2.1 信号量_semaphore
# ### 信号量 Semaphore 本质上就是锁,只不过是多个进程上多把锁,可以控制上锁的数量
"""Semaphore = lock + 数量 """
from multiprocessing import Semaphore , Process
import time , random
"""
# 同一时间允许多个进程上5把锁
sem = Semaphore(5)
#上锁
sem.acquire()
print("执行操作 ... ")
#解锁
sem.release()
"""
def singsong_ktv(person,sem):
# 上锁
sem.acquire()
print("{}进入了唱吧ktv , 正在唱歌 ~".format(person))
# 唱一段时间
time.sleep( random.randrange(4,8) ) # 4 5 6 7
print("{}离开了唱吧ktv , 唱完了 ... ".format(person))
# 解锁
sem.release()
if __name__ == "__main__":
sem = Semaphore(5)
lst = ["赵凤勇" , "沈思雨", "赵万里" , "张宇" , "假率先" , "孙杰龙" , "陈璐" , "王雨涵" , "杨元涛" , "刘一凤" ]
for i in lst:
p = Process(target=singsong_ktv , args = (i , sem) )
p.start()
"""
# 总结: Semaphore 可以设置上锁的数量 , 同一时间上多把锁
创建进程时,是异步并发,执行任务时,是同步程序;
"""
# 赵万里进入了唱吧ktv , 正在唱歌 ~
# 赵凤勇进入了唱吧ktv , 正在唱歌 ~
# 张宇进入了唱吧ktv , 正在唱歌 ~
# 沈思雨进入了唱吧ktv , 正在唱歌 ~
# 孙杰龙进入了唱吧ktv , 正在唱歌 ~
2.2 事件_红绿灯效果
# ### 事件 (Event)
"""
# 阻塞事件 :
e = Event()生成事件对象e
e.wait()动态给程序加阻塞 , 程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值是False]
# 如果是True 不加阻塞
# 如果是False 加阻塞
# 控制这个属性的值
# set()方法 将这个属性的值改成True
# clear()方法 将这个属性的值改成False
# is_set()方法 判断当前的属性是否为True (默认上来是False)
"""
from multiprocessing import Process,Event
import time , random
# 1
'''
e = Event()
# 默认属性值是False.
print(e.is_set())
# 判断内部成员属性是否是False
e.wait()
# 如果是False , 代码程序阻塞
print(" 代码执行中 ... ")
'''
# 2
'''
e = Event()
# 将这个属性的值改成True
e.set()
# 判断内部成员属性是否是True
e.wait()
# 如果是True , 代码程序不阻塞
print(" 代码执行中 ... ")
# 将这个属性的值改成False
e.clear()
e.wait()
print(" 代码执行中 .... 2")
'''
# 3
"""
e = Event()
# wait(3) 代表最多等待3秒;
e.wait(3)
print(" 代码执行中 .... 3")
"""
# ### 模拟经典红绿灯效果
# 红绿灯切换
def traffic_light(e):
print("红灯亮")
while True:
if e.is_set():
# 绿灯状态 -> 切红灯
time.sleep(1)
print("红灯亮")
# True => False
e.clear()
else:
# 红灯状态 -> 切绿灯
time.sleep(1)
print("绿灯亮")
# False => True
e.set()
# e = Event()
# traffic_light(e)
# 车的状态
def car(e,i):
# 判断是否是红灯,如果是加上wait阻塞
if not e.is_set():
print("car{} 在等待 ... ".format(i))
e.wait()
# 否则不是,代表绿灯通行;
print("car{} 通行了 ... ".format(i))
"""
# 1.全国红绿灯
if __name__ == "__main__":
e = Event()
# 创建交通灯
p1 = Process(target=traffic_light , args=(e,))
p1.start()
# 创建小车进程
for i in range(1,21):
time.sleep(random.randrange(2))
p2 = Process(target=car , args=(e,i))
p2.start()
"""
# 2.包头红绿灯,没有车的时候,把红绿灯关了,省电;
if __name__ == "__main__":
lst = []
e = Event()
# 创建交通灯
p1 = Process(target=traffic_light , args=(e,))
# 设置红绿灯为守护进程
p1.daemon = True
p1.start()
# 创建小车进程
for i in range(1,21):
time.sleep(random.randrange(2))
p2 = Process(target=car , args=(e,i))
lst.append(p2)
p2.start()
# 让所有的小车全部跑完,把红绿灯炸飞
print(lst)
for i in lst:
i.join()
print("关闭成功 .... ")
事件知识点:
# 阻塞事件 :
e = Event()生成事件对象e
e.wait()动态给程序加阻塞 , 程序当中是否加阻塞完全取决于该对象中的is_set() [默认返回值是False]
# 如果是True 不加阻塞
# 如果是False 加阻塞
# 控制这个属性的值
# set()方法 将这个属性的值改成True
# clear()方法 将这个属性的值改成False
# is_set()方法 判断当前的属性是否为True (默认上来是False)
3. queue进程队列
# ### 进程队列(进程与子进程是相互隔离的,如果两者想要进行通信,可以利用队列实现)
from multiprocessing import Process,Queue
# 引入线程模块; 为了捕捉queue.Empty异常;
import queue
# 1.基本语法
"""顺序: 先进先出,后进后出"""
# 创建进程队列
q = Queue()
# put() 存放
q.put(1)
q.put(2)
q.put(3)
# get() 获取
"""在获取不到任何数据时,会出现阻塞"""
# print( q.get() )
# print( q.get() )
# print( q.get() )
# print( q.get() )
# get_nowait() 拿不到数据报异常
"""[windows]效果正常 [linux]不兼容"""
try:
print( q.get_nowait() )
print( q.get_nowait() )
print( q.get_nowait() )
print( q.get_nowait() )
except : #queue.Empty
pass
# put_nowait() 非阻塞版本的put
# 设置当前队列最大长度为3 ( 元素个数最多是3个 )
"""在指定队列长度的情况下,如果塞入过多的数据,会导致阻塞"""
# q2 = Queue(3)
# q2.put(111)
# q2.put(222)
# q2.put(333)
# q2.put(444)
"""使用put_nowait 在队列已满的情况下,塞入数据会直接报错"""
q2 = Queue(3)
try:
q2.put_nowait(111)
q2.put_nowait(222)
q2.put_nowait(333)
q2.put_nowait(444)
except:
pass
# 2.进程间的通信IPC
def func(q):
# 2.子进程获取主进程存放的数据
res = q.get()
print(res,"<22>")
# 3.子进程中存放数据
q.put("刘一缝")
if __name__ == "__main__":
q3 = Queue()
p = Process(target=func,args=(q3,))
p.start()
# 1.主进程存入数据
q3.put("赵凤勇")
# 为了等待子进程把数据存放队列后,主进程在获取数据;
p.join()
# 4.主进程获取子进程存放的数据
print(q3.get() , "<33>")
小提示: 一般主进程比子进程执行的快一些
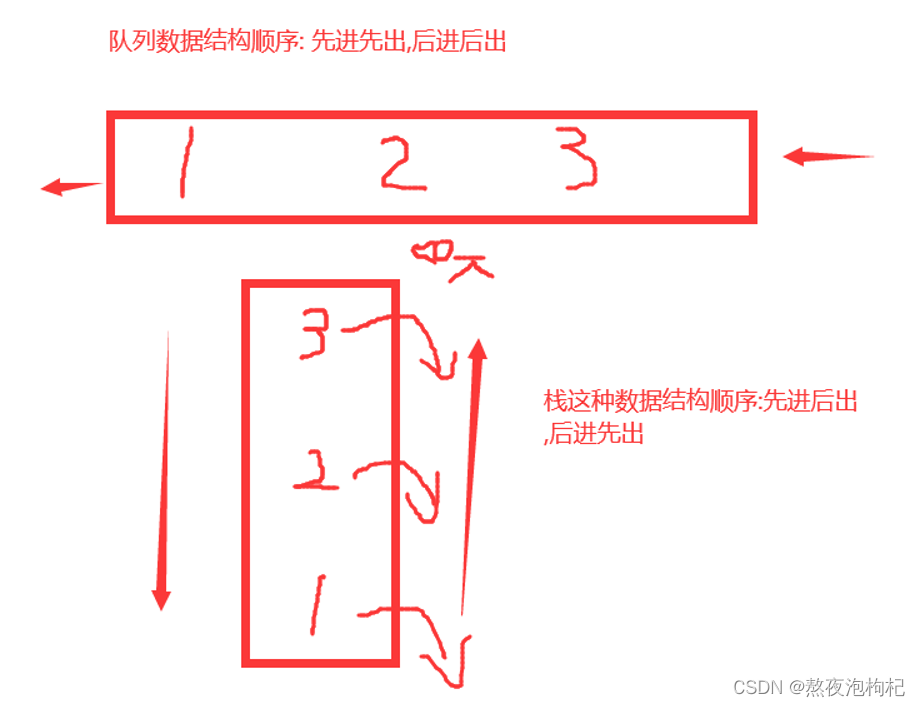
队列知识点:
# 进程间通信 IPC
# IPC Inter-Process Communication
# 实现进程之间通信的两种机制:
# 管道 Pipe
# 队列 Queue
# put() 存放
# get() 获取
# get_nowait() 拿不到报异常
# put_nowait() 非阻塞版本的put
q.empty() 检测是否为空 (了解)
q.full() 检测是否已经存满 (了解)
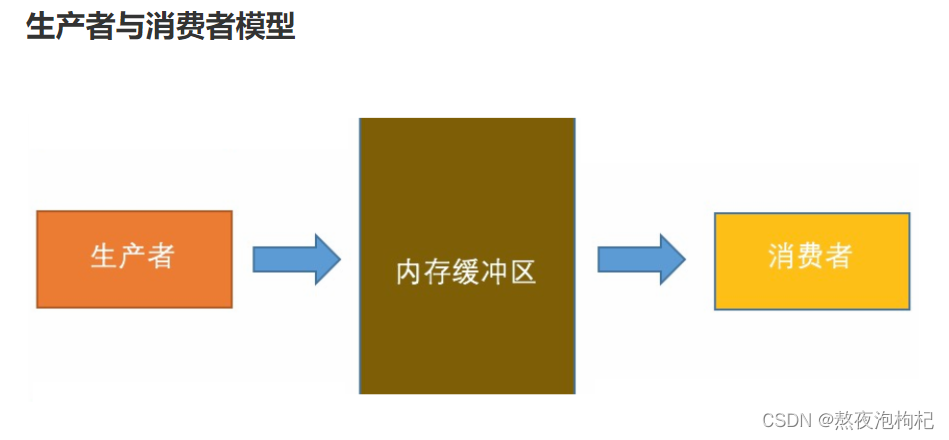
4. 生产者消费者模型
# ### 生产者和消费者模型
"""
# 爬虫案例
1号进程负责抓取其他多个网站中相关的关键字信息,正则匹配到队列中存储(mysql)
2号进程负责把队列中的内容拿取出来,将经过修饰后的内容布局到自个的网站中
1号进程可以理解成生产者
2号进程可以理解成消费者
从程序上来看
生产者负责存储数据 (put)
消费者负责获取数据 (get)
生产者和消费者比较理想的模型:
生产多少,消费多少 . 生产数据的速度 和 消费数据的速度 相对一致
"""
# 1.基础版生产着消费者模型
"""问题 : 当前模型,程序不能正常终止 """
"""
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p1.start()
p2.start()
p2.join()
"""
# 2.优化模型
"""特点 : 手动在队列的最后,加入标识None, 终止消费者模型"""
"""
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
# 如果最后一次获取的数据是None , 代表队列已经没有更多数据可以获取了,终止循环;
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p1.start()
p2.start()
p2.join()
q.put(None) # 香蕉0 香蕉1 香蕉2 香蕉3 香蕉4 None
"""
# 3.多个生产者和消费者
""" 问题 : 虽然可以解决问题 , 但是需要加入多个None , 代码冗余"""
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
# 如果最后一次获取的数据是None , 代表队列已经没有更多数据可以获取了,终止循环;
if food is None:
break
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = Queue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p1_1 = Process( target=consumer,args=(q , "赵世超") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p2_2 = Process( target=producer,args=(q , "赵凤勇" , "大蒜" ) )
p1.start()
p1_1.start()
p2.start()
p2_2.start()
# 等待所有数据填充完毕
p2.join()
p2_2.join()
# 把None 关键字放在整个队列的最后,作为跳出消费者循环的标识符;
q.put(None) # 给第一个消费者加一个None , 用来终止
q.put(None) # 给第二个消费者加一个None , 用来终止
# ...
5. joinablequeue队列使用
# ### JoinableQueue 队列
"""
put 存放
get 获取
task_done 计算器属性值-1
join 配合task_done来使用 , 阻塞
put 一次数据, 队列的内置计数器属性值+1
get 一次数据, 通过task_done让队列的内置计数器属性值-1
join: 会根据队列计数器的属性值来判断是否阻塞或者放行
队列计数器属性是 等于 0 , 代码不阻塞放行
队列计数器属性是 不等 0 , 意味着代码阻塞
"""
from multiprocessing import JoinableQueue
jq = JoinableQueue()
jq.put("王同培") # +1
jq.put("王伟") # +2
print(jq.get())
print(jq.get())
# print(jq.get()) 阻塞
jq.task_done() # -1
jq.task_done() # -1
jq.join()
print(" 代码执行结束 .... ")
# ### 2.使用JoinableQueue 改造生产着消费者模型
from multiprocessing import Process,Queue
import time,random
# 消费者模型
def consumer(q,name):
while True:
# 获取队列中的数据
food = q.get()
time.sleep(random.uniform(0.1,1))
print("{}吃了{}".format(name,food))
# 让队列的内置计数器属性-1
q.task_done()
# 生产者模型
def producer(q,name,food):
for i in range(5):
time.sleep(random.uniform(0.1,1))
# 展示生产的数据
print( "{}生产了{}".format( name , food+str(i) ) )
# 存储生产的数据在队列中
q.put(food+str(i))
if __name__ == "__main__":
q = JoinableQueue()
p1 = Process( target=consumer,args=(q , "赵万里") )
p2 = Process( target=producer,args=(q , "赵沈阳" , "香蕉" ) )
p1.daemon = True
p1.start()
p2.start()
p2.join()
# 必须等待队列中的所有数据全部消费完毕,再放行
q.join()
print("程序结束 ... ")
6. 总结
ipc可以让进程之间进行通信 lock其实也让进程之间进行通信了,多个进程去抢一把锁,一个进程抢到 这 把锁了,其他的进程就抢不到这把锁了,进程通过socket底层互相发 消息,告诉其他进程当前状态已经被锁定了,不能再强了。 进程之间默认是隔离的,不能通信的,如果想要通信,必须通过ipc的 方式(lock、joinablequeue、Manager)
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
详解Python中的四种队列
队列是一种只允许在一端进行插入操作,而在另一端进行删除操作的线性表. 在Python文档中搜索队列(queue)会发现,Python标准库中包含了四种队列,分别是queue.Queue / asyncio.Queue / multiprocessing.Queue / collections.deque. collections.deque deque是双端队列(double-ended queue)的缩写,由于两端都能编辑,deque既可以用来实现栈(stack)也可以用来实现队列(queue
-
python队列Queue的详解
Queue Queue是python标准库中的线程安全的队列(FIFO)实现,提供了一个适用于多线程编程的先进先出的数据结构,即队列,用来在生产者和消费者线程之间的信息传递 基本FIFO队列 class Queue.Queue(maxsize=0) FIFO即First in First Out,先进先出.Queue提供了一个基本的FIFO容器,使用方法很简单,maxsize是个整数,指明了队列中能存放的数据个数的上限.一旦达到上限,插入会导致阻塞,直到队列中的数据被消费掉.如果maxsize小
-

python 队列详解及实例代码
队列特性:先进先出(FIFO)--先进队列的元素先出队列.来源于我们生活中的队列(先排队的先办完事). Queue模块最常与threading模块一起构成生产-消费者模型,提供了一个适用于多线程编程的先进先出的数据结构,即队列. 该模块源码中包含5个类: 其中,Empty和Full是两个异常类,当队列的Queue.get(block=0)或者调用get_nowait()时,如果队列为空,则抛EmptyException异常. 同理,当队列的Queue.put(block=0)或者调用put_no
-
python队列queue模块详解
队列queue 多应用在多线程应用中,多线程访问共享变量.对于多线程而言,访问共享变量时,队列queue是线程安全的.从queue队列的具体实现中,可以看出queue使用了1个线程互斥锁(pthread.Lock()),以及3个条件标量(pthread.condition()),来保证了线程安全. queue队列的互斥锁和条件变量,可以参考另一篇文章:python线程中同步锁 queue的用法如下: import Queque a=[1,2,3] device_que=Queque.queue(
-
Python算法应用实战之队列详解
队列(queue) 队列是先进先出(FIFO, First-In-First-Out)的线性表,在具体应用中通常用链表或者数组来实现,队列只允许在后端(称为rear)进行插入操作,在前端(称为front)进行删除操作,队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加(摘录维基百科). 如图所示 队列的接口 一个队列至少需要如下接口: 接口 描述 add(x) 入队 delete() 出队 clear() 清空队列 isEmpty() 判断队列是否为空 isFull() 判断
-
Python全栈之队列详解
目录 1. lock互斥锁 2. 事件_红绿灯效果 2.1 信号量_semaphore 2.2 事件_红绿灯效果 3. queue进程队列 4. 生产者消费者模型 5. joinablequeue队列使用 6. 总结 1. lock互斥锁 知识点: lock.acquire()# 上锁 lock.release()# 解锁 #同一时间允许一个进程上一把锁 就是Lock 加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲速度却保证了数据
-
Python全栈之线程详解
目录 1. 线程的概念 1.1 Manager_进程通信 1.2 线程的概念 2. 线程的基本使用 3. 自定义线程_守护线程 3.1 自定义线程 3.2 守护线程 4. 线程安全问题 4.1 线程安全问题 4.2 Semaphore_信号量 5. 死锁_互斥锁_递归锁 6. 线程事件 总结 1. 线程的概念 1.1 Manager_进程通信 # ### Manager ( list 列表 , dict 字典 ) 进程之间共享数据 from multiprocessing import Proc
-
Python全栈之运算符详解
目录 1. 算数_比较_赋值_成员 1.1 算数运算符 1.2 比较运算符 1.3 赋值运算符 1.4 成员运算符 2. 身份运算符 小提示: 3. 逻辑运算符 3.1 位运算符 3.2 小总结 4. 代码块_单项_双项分支 4.1 代码块 4.2 流程控制 4.3 单项分支 4.4 双项分支 5. 小作业 总结 1. 算数_比较_赋值_成员 1.1 算数运算符 算数运算符: + - * / // % ** # + var1 = 7 var2 = 90 res = var1 + var2 pri
-
C语言 表、栈和队列详解及实例代码
C语言 表.栈和队列详解 表ADT 形如A1,A2,A3-An的表,这个表的大小为n,而大小为0的表称为空表,非空表中,Ai+1后继Ai,Ai-1前驱Ai,表ADT的相关操有PrintList打印表中的元素:CreateEmpty创建一个空表:Find返回关键字首次出现的位置:Insert和Delete从表的某个位置插入和删除某个关键字. 对表的所有操作都可以通过使用数组来实现,但在这里使用链表的方式来实现.链表(linked list)由一系列不必在内存中相连的结构组成,每个结构均含有元素和指
-
C语言分别实现栈和队列详解流程
目录 什么是栈 栈的结构图示 栈的实现 创建栈的结构体 初始化栈 入栈 出栈 获取栈顶元素 获取栈中有效元素个数 检测栈是否为空 栈的销毁 什么是队列? 队列的实现 创建队列结构体 初始化队列 队尾入队列 队头出队列 获取队列头部元素 获取队列尾部元素 获取队列中元素个数 检测队列是否为空 销毁队列 什么是栈 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素的操作.进行数据插入和删除的一端称为栈顶,另一端称为栈底.栈中的数据元素遵守先进后出LIFO(Last In First Out
-
c语言数据结构之栈和队列详解(Stack&Queue)
目录 简介 栈 一.栈的基本概念 1.栈的定义 2.栈的常见基本操作 二.栈的顺序存储结构 1.栈的顺序存储 2.顺序栈的基本算法 3.共享栈(两栈共享空间) 三.栈的链式存储结构 1.链栈 2.链栈的基本算法 3.性能分析 四.栈的应用——递归 1.递归的定义 2.斐波那契数列 五.栈的应用——四则运算表达式求值 1.后缀表达式计算结果 2.中缀表达式转后缀表达式 队列 一.队列的基本概念 1.队列的定义 2.队列的常见基本操作 二.队列的顺序存储结构 1.顺序队列 2.循环队列 3.循环队列
-
Javascript数据结构之栈和队列详解
目录 前言 栈(stack) 栈实现 解决实际问题 栈的另外应用 简单队列(Queue) 队列实现 队列应用 - 树的广度优先搜索(breadth-first search,BFS) 优先队列 优先队列实现 线性数据结构实现优先队列 Heap(堆)数据结构实现优先队列 代码实现一个二叉堆 小顶堆在 React Scheduler 事务调度的包应用 最后 前言 我们实际开发中,比较熟悉的数据结构是数组.一般情况下够用了.但如果遇到复杂的问题,数组就捉襟见肘了.在解决一个复杂的实际问题的时候,选择一
-
Python实现栈的方法详解【基于数组和单链表两种方法】
本文实例讲述了Python实现栈的方法.分享给大家供大家参考,具体如下: 前言 使用Python 实现栈. 两种实现方式: 基于数组 - 数组同时基于链表实现 基于单链表 - 单链表的节点时一个实例化的node 对象 完整代码可见GitHub: https://github.com/GYT0313/Python-DataStructure/tree/master/5-stack 目录结构: 注:一个完整的代码并不是使用一个py文件,而使用了多个文件通过继承方式实现. 1. 超类接口代码 arra
-
Python数据结构之队列详解
目录 0. 学习目标 1. 队列的基本概念 1.1 队列的基本概念 1.2 队列抽象数据类型 1.3 队列的应用场景 2. 队列的实现 2.1 顺序队列的实现 2.2 链队列的实现 2.3 队列的不同实现对比 3. 队列应用 3.1 顺序队列的应用 3.2 链队列的应用 3.3 利用队列基本操作实现复杂算法 0. 学习目标 栈和队列是在程序设计中常见的数据类型,从数据结构的角度来讲,栈和队列也是线性表,是操作受限的线性表,它们的基本操作是线性表操作的子集,但从数据类型的角度来讲,它们与线性表又有
-
Python生成随机数的方法详解(最全)
目录 使用 random 模块 使用 NumPy 库 使用 secrets 模块 使用 random.org 网站 使用 random.choices()方法 python生成随机数都有哪些办法呢 使用 random 模块:random模块是python内置的模块,使用方法如random.randint()生成一个随机整数. 使用 NumPy 库:NumPy 是一个强大的数值计算库,它提供了生成随机数的功能,例如numpy.random.randint()生成一个随机整数. 使用 secrets