详解基于python的全局与局部序列比对的实现(DNA)
程序能实现什么
a.完成gap值的自定义输入以及两条需比对序列的输入
b.完成得分矩阵的计算及输出
c.输出序列比对结果
d.使用matplotlib对得分矩阵路径的绘制
一、实现步骤
1.用户输入步骤
a.输入自定义的gap值
b.输入需要比对的碱基序列1(A,T,C,G)换行表示输入完成
b.输入需要比对的碱基序列2(A,T,C,G)换行表示输入完成
输入(示例):

2.代码实现步骤
1.获取到用户输入的gap,s以及t
2.调用构建得分矩阵函数,得到得分矩阵以及方向矩阵
3.将得到的得分矩阵及方向矩阵作为参数传到回溯函数中开始回溯得到路径,路径存储使用的是全局变量,存的仍然是方向而不是坐标位置减少存储开销,根据全局变量中存储的方向将比对结果输出。
4.根据全局变量中存储的方向使用matplotlib画出路径
全局比对代码如下:
import matplotlib.pyplot as plt
import numpy as np
#定义全局变量列表finalList存储最后回溯的路径 finalOrder1,finalOrder2存储最后的序列 finalRoad用于存储方向路径用于最后画图
def createList():
global finalList
global finalOrder1
global finalOrder2
global finalRoad
finalList = []
finalOrder1 = []
finalOrder2 = []
finalRoad = []
#创建A G C T 对应的键值对,方便查找计分矩阵中对应的得分
def createDic():
dic = {'A':0,'G':1,'C':2,'T':3}
return dic
#构建计分矩阵
# A G C T
def createGrade():
grade = np.matrix([[10,-1,-3,-4],
[-1,7,-5,-3],
[-3,-5,9,0],
[-4,-3,0,8]])
return grade
#计算两个字符的相似度得分函数
def getGrade(a,b):
dic = createDic() # 碱基字典 方便查找计分矩阵
grade = createGrade() # 打分矩阵grade
return grade[dic[a],dic[b]]
#构建得分矩阵函数 参数为要比较序列、自定义的gap值
def createMark(s,t,gap):
a = len(s) #获取序列长度a,b
b = len(t)
mark = np.zeros((a+1,b+1)) #初始化全零得分矩阵
direction = np.zeros((a+1,b+1,3)) #direction矩阵用来存储得分矩阵中得分来自的方向 第一个表示左方 第二个表示左上 第三个表示上方 1表示能往哪个方向去
#由于得分可能会来自多个方向,所以使用三维矩阵存储
direction[0][0] = -1 #确定回溯时的结束条件 即能够走到方向矩阵的值为-1
mark[0,:] = np.fromfunction(lambda x, y: gap * (x + y), (1, b + 1), dtype=int) #根据gap值将得分矩阵第一行计算出
mark[:,0] = np.fromfunction(lambda x, y: gap * (x + y), (1, a + 1), dtype=int) #根据gap值将得分矩阵第一列计算出
for i in range(1,b+1):
direction[0,i,0] = 1
for i in range(1, a + 1):
direction[i, 0, 2] = 1
for i in range(1,a+1):
for j in range(1,b+1):
threeMark = [mark[i][j-1],mark[i-1][j-1],mark[i-1][j]] #threeMark表示现在所要计算得分的位置的左边 左上 上边的得分
threeGrade = [gap,getGrade(s[i-1],t[j-1]),gap] #threeGrade表示经过需要计算得左边 左上 上边的空位以及相似度得分
finalGrade = np.add(threeMark,threeGrade) #finalGrade表示最终来自三个方向上的得分
mark[i][j] = max(finalGrade) #选取三个方向上的最大得分存入得分矩阵
#可能该位置的得分可以由多个方向得来,所以进行判断并循环赋值
for k in range(0,len([y for y,x in enumerate(finalGrade) if x == max(finalGrade)])):
directionList = [y for y,x in enumerate(finalGrade) if x == max(finalGrade)]
direction[i][j][directionList[k]] = 1
return mark,direction
#回溯函数 参数分别为 得分矩阵 方向矩阵 现在所处得分矩阵的位置 以及两个序列
def remount(mark,direction,i,j,s,t):
if direction[i][j][0] == 1 :
if direction[i][j-1][0] == -1: #如果该位置指向左边 先判断其左边是否是零点
finalList.append(0) #如果是 将该路径存入路径列表
finalList.reverse() #将列表反过来得到从零点开始的路径
index1 = 0 #记录现在所匹配序列s的位置 因为两个字符串可能是不一样长的
index2 = 0 #记录现在所匹配序列t的位置
for k in finalList:
if k == 0 :
finalOrder1.append("-")
finalOrder2.append(t[index2])
index2 += 1
if k == 1 :
finalOrder1.append(s[index1])
finalOrder2.append(t[index2])
index1 += 1
index2 += 1
if k == 2 :
finalOrder1.append(s[index1])
finalOrder2.append("-")
index1 += 1
finalList.reverse() # 将原来反转的路径再返回来
finalRoad.append(np.array(finalList)) # 将此次的路径添加到最终路径记录用于最后画图
finalList.pop() #输出后将当前方向弹出 并回溯
return
else :
finalList.append(0) #如果不是零点 则将该路径加入路径矩阵,继续往下走
remount(mark,direction,i,j-1,s,t)
finalList.pop() #该方向走完后将这个方向弹出 继续下一轮判断 下面两个大的判断同理
if direction[i][j][1] == 1 :
if direction[i-1][j-1][0] == -1:
finalList.append(1)
finalList.reverse() # 将列表反过来得到从零点开始的路径
index1 = 0 # 记录现在所匹配序列s的位置 因为两个字符串可能是不一样长的
index2 = 0 # 记录现在所匹配序列t的位置
for k in finalList:
if k == 0 :
finalOrder1.append("-")
finalOrder2.append(t[index2])
index2 += 1
if k == 1 :
finalOrder1.append(s[index1])
finalOrder2.append(t[index2])
index1 += 1
index2 += 1
if k == 2 :
finalOrder1.append(s[index1])
finalOrder2.append("-")
index1 += 1
finalList.reverse() # 将原来反转的路径再返回来
finalRoad.append(np.array(finalList)) # 将此次的路径添加到最终路径记录用于最后画图
finalList.pop()
return
else :
finalList.append(1)
remount(mark,direction,i-1,j-1,s,t)
finalList.pop()
if direction[i][j][2] == 1 :
if direction[i-1][j][0] == -1:
finalList.append(2)
finalList.reverse() # 将列表反过来得到从零点开始的路径
index1 = 0 # 记录现在所匹配序列s的位置 因为两个字符串可能是不一样长的
index2 = 0 # 记录现在所匹配序列t的位置
for k in finalList:
if k == 0 :
finalOrder1.append("-")
finalOrder2.append(t[index2])
index2 += 1
if k == 1 :
finalOrder1.append(s[index1])
finalOrder2.append(t[index2])
index1 += 1
index2 += 1
if k == 2 :
finalOrder1.append(s[index1])
finalOrder2.append("-")
index1 += 1
finalList.reverse() # 将原来反转的路径再返回来
finalRoad.append(np.array(finalList)) # 将此次的路径添加到最终路径记录用于最后画图
finalList.pop()
return
else :
finalList.append(2)
remount(mark,direction,i-1,j,s,t)
finalList.pop()
#画箭头函数
def arrow(ax,sX,sY,aX,aY):
ax.arrow(sX,sY,aX,aY,length_includes_head=True, head_width=0.15, head_length=0.25, fc='w', ec='b')
#画图函数
def drawArrow(mark, direction, a, b, s, t):
#a是s的长度为4 b是t的长度为6
fig = plt.figure()
ax = fig.add_subplot(111)
val_ls = range(a+2)
scale_ls = range(b+2)
index_ls = []
index_lsy = []
for i in range(a):
if i == 0:
index_lsy.append('#')
index_lsy.append(s[a-i-1])
index_lsy.append('0')
for i in range(b):
if i == 0:
index_ls.append('#')
index_ls.append('0')
index_ls.append(t[i])
plt.xticks(scale_ls, index_ls) #设置坐标字
plt.yticks(val_ls, index_lsy)
for k in range(1,a+2):
y = [k for i in range(0,b+1)]
x = [x for x in range(1,b+2)]
ax.scatter(x, y, c='y')
for i in range(1,a+2):
for j in range(1,b+2):
ax.text(j,a+2-i,int(mark[i-1][j-1]))
lX = b+1
lY = 1
for n in range(0,len(finalRoad)):
for m in (finalRoad[n]):
if m == 0:
arrow(ax,lX,lY,-1,0)
lX = lX - 1
elif m == 1:
arrow(ax,lX,lY,-1,1)
lX = lX - 1
lY = lY + 1
elif m == 2:
arrow(ax, lX, lY, 0, 1)
lY = lY + 1
lX = b + 1
lY = 1
ax.set_xlim(0, b + 2) # 设置图形的范围,默认为[0,1]
ax.set_ylim(0, a + 2) # 设置图形的范围,默认为[0,1]
ax.set_aspect('equal') # x轴和y轴等比例
plt.show()
plt.tight_layout()
if __name__ == '__main__':
createList()
print("Please enter gap:")
gap = int(input()) #获取gap值 转换为整型 tip:刚开始就是因为这里没有进行类型导致后面的计算部分报错
print("Please enter sequence 1:")
s = input() #获取用户输入的第一条序列
print("Please enter sequence 2:")
t = input() #获取用户输入的第二条序列
a = len(s) #获取s的长度
b = len(t) #获取t的长度
mark,direction = createMark(s,t,gap)
print("The scoring matrix is as follows:") #输出得分矩阵
print(mark)
remount(mark,direction,a,b,s,t) #调用回溯函数
c = a if a > b else b #判断有多少种比对结果得到最终比对序列的长度
total = int(len(finalOrder1)/c)
for i in range(1,total+1): #循环输出比对结果
k = str(i)
print("Sequence alignment results "+k+" is:")
print(finalOrder1[(i-1)*c:i*c])
print(finalOrder2[(i-1)*c:i*c])
drawArrow(mark, direction, a, b, s, t)
局部比对代码如下
import matplotlib.pyplot as plt
import numpy as np
import operator
#在局部比对中 回溯结束的条件是方向矩阵中该位置的值全为0
#定义全局变量列表finalList存储最后回溯的路径 finalOrder1,finalOrder2存储最后的序列
def createList():
global finalList
global finalOrder1
global finalOrder2
global finalRoad
finalList = []
finalOrder1 = []
finalOrder2 = []
finalRoad = []
#创建A G C T 对应的键值对,方便查找计分矩阵中对应的得分
def createDic():
dic = {'A':0,'G':1,'C':2,'T':3}
return dic
#构建计分矩阵
# A G C T
def createGrade():
grade = np.matrix([[10,-1,-3,-4],
[-1,7,-5,-3],
[-3,-5,9,0],
[-4,-3,0,8]])
return grade
#计算两个字符的相似度得分函数
def getGrade(a,b):
dic = createDic() # 碱基字典 方便查找计分矩阵
grade = createGrade() # 打分矩阵grade
return grade[dic[a],dic[b]]
#构建得分矩阵函数 参数为要比较序列、自定义的gap值
def createMark(s,t,gap):
a = len(s) #获取序列长度a,b
b = len(t)
mark = np.zeros((a+1,b+1)) #初始化全零得分矩阵
direction = np.zeros((a+1,b+1,3)) #direction矩阵用来存储得分矩阵中得分来自的方向 第一个表示左方 第二个表示左上 第三个表示上方 1表示能往哪个方向去
#由于得分可能会来自多个方向,所以使用三维矩阵存
for i in range(1,a+1):
for j in range(1,b+1):
threeMark = [mark[i][j-1],mark[i-1][j-1],mark[i-1][j]] #threeMark表示现在所要计算得分的位置的左边 左上 上边的得分
threeGrade = [gap,getGrade(s[i-1],t[j-1]),gap] #threeGrade表示经过需要计算得左边 左上 上边的空位以及相似度得分
finalGrade = np.add(threeMark,threeGrade) #finalGrade表示最终来自三个方向上的得分
if max(finalGrade) >= 0: #如果该最大值是大于0的则 选取三个方向上的最大得分存入得分矩阵 否则不对矩阵进行修改
mark[i][j] = max(finalGrade)
for k in range(0,len([y for y,x in enumerate(finalGrade) if x == max(finalGrade)])): #可能该位置的得分可以由多个方向得来,所以进行判断并循环赋值
directionList = [y for y,x in enumerate(finalGrade) if x == max(finalGrade)]
direction[i][j][directionList[k]] = 1
return mark,direction
#回溯函数 参数分别为 得分矩阵 方向矩阵 现在所处得分矩阵的位置 以及两个序列
def remount(mark,direction,i,j,s,t):
if direction[i][j][0] == 1 :
if all(direction[i][j-1] == [0,0,0]): #如果该位置指向左边 先判断其左边是否是零点
finalList.append(0) #如果是 将该路径存入路径列表
finalList.reverse() #将列表反过来得到从零点开始的路径
index1 = i #记录现在所匹配序列s的位置 因为两个字符串可能是不一样长的
index2 = j-1 #记录现在所匹配序列t的位置
for k in finalList:
if k == 0 :
finalOrder1.append("-")
finalOrder2.append(t[index2])
index2 += 1
if k == 1 :
finalOrder1.append(s[index1])
finalOrder2.append(t[index2])
index1 += 1
index2 += 1
if k == 2 :
finalOrder1.append(s[index1])
finalOrder2.append("-")
index1 += 1
finalList.reverse()
finalRoad.append(np.array(finalList)) # 将此次的路径添加到最终路径记录用于最后画图
finalList.pop() #输出后将当前方向弹出 并回溯
return
else :
finalList.append(0) #如果不是零点 则将该路径加入路径矩阵,继续往下走
remount(mark,direction,i,j-1,s,t)
finalList.pop() #该方向走完后将这个方向弹出 继续下一轮判断 下面两个大的判断同理
if direction[i][j][1] == 1 :
if all(direction[i-1][j-1] == [0,0,0]):
finalList.append(1)
finalList.reverse() # 将列表反过来得到从零点开始的路径
index1 = i-1 # 记录现在所匹配序列s的位置 因为两个字符串可能是不一样长的
index2 = j-1 # 记录现在所匹配序列t的位置
for k in finalList:
if k == 0 :
finalOrder1.append("-")
finalOrder2.append(t[index2])
index2 += 1
if k == 1 :
finalOrder1.append(s[index1])
finalOrder2.append(t[index2])
index1 += 1
index2 += 1
if k == 2 :
finalOrder1.append(s[index1])
finalOrder2.append("-")
index1 += 1
finalList.reverse()
finalRoad.append(np.array(finalList)) # 将此次的路径添加到最终路径记录用于最后画图
finalList.pop()
return
else :
finalList.append(1)
remount(mark,direction,i-1,j-1,s,t)
finalList.pop()
if direction[i][j][2] == 1 :
if all(direction[i-1][j] == [0,0,0]):
finalList.append(2)
finalList.reverse() # 将列表反过来得到从零点开始的路径
index1 = i-1 # 记录现在所匹配序列s的位置 因为两个字符串可能是不一样长的
index2 = j # 记录现在所匹配序列t的位置
for k in finalList:
if k == 0 :
finalOrder1.append("-")
finalOrder2.append(t[index2])
index2 += 1
if k == 1 :
finalOrder1.append(s[index1])
finalOrder2.append(t[index2])
index1 += 1
index2 += 1
if k == 2 :
finalOrder1.append(s[index1])
finalOrder2.append("-")
index1 += 1
finalList.reverse()
finalRoad.append(np.array(finalList)) # 将此次的路径添加到最终路径记录用于最后画图
finalList.pop()
return
else :
finalList.append(2)
remount(mark,direction,i-1,j,s,t)
finalList.pop()
#画箭头函数
def arrow(ax,sX,sY,aX,aY):
ax.arrow(sX,sY,aX,aY,length_includes_head=True, head_width=0.15, head_length=0.25, fc='w', ec='b')
#画图函数
def drawArrow(mark, direction, a, b, s, t,mx,my):
#a是s的长度为4 b是t的长度为6
fig = plt.figure()
ax = fig.add_subplot(111)
val_ls = range(a+2)
scale_ls = range(b+2)
index_ls = []
index_lsy = []
for i in range(a):
if i == 0:
index_lsy.append('#')
index_lsy.append(s[a-i-1])
index_lsy.append('0')
for i in range(b):
if i == 0:
index_ls.append('#')
index_ls.append('0')
index_ls.append(t[i])
plt.xticks(scale_ls, index_ls) #设置坐标字
plt.yticks(val_ls, index_lsy)
for k in range(1,a+2):
y = [k for i in range(0,b+1)]
x = [x for x in range(1,b+2)]
ax.scatter(x, y, c='y')
for i in range(1,a+2):
for j in range(1,b+2):
ax.text(j,a+2-i,int(mark[i-1][j-1]))
lX = my + 1
lY = a - mx + 1
for n in range(0,len(finalRoad)):
for m in (finalRoad[n]):
if m == 0:
arrow(ax,lX,lY,-1,0)
lX = lX - 1
elif m == 1:
arrow(ax,lX,lY,-1,1)
lX = lX - 1
lY = lY + 1
elif m == 2:
arrow(ax, lX, lY, 0, 1)
lY = lY + 1
lX = b + 1
lY = 1
ax.set_xlim(0, b + 2) # 设置图形的范围,默认为[0,1]
ax.set_ylim(0, a + 2) # 设置图形的范围,默认为[0,1]
ax.set_aspect('equal') # x轴和y轴等比例
plt.show()
plt.tight_layout()
if __name__ == '__main__':
createList()
print("Please enter gap:")
gap = int(input()) #获取gap值 转换为整型 tip:刚开始就是因为这里没有进行类型导致后面的计算部分报错
print("Please enter sequence 1:")
s = input() #获取用户输入的第一条序列
print("Please enter sequence 2:")
t = input() #获取用户输入的第二条序列
a = len(s) #获取s的长度
b = len(t) #获取t的长度
mark,direction = createMark(s,t,gap)
print("The scoring matrix is as follows:") #输出得分矩阵
print(mark)
maxDirection = np.argmax(mark) #获取最大值的位置
i = int(maxDirection/(b+1))
j = int(maxDirection - i*(b+1))
remount(mark,direction,i,j,s,t) #调用回溯函数
print(finalOrder1)
print(finalOrder2)
drawArrow(mark, direction, a, b, s, t, i, j)
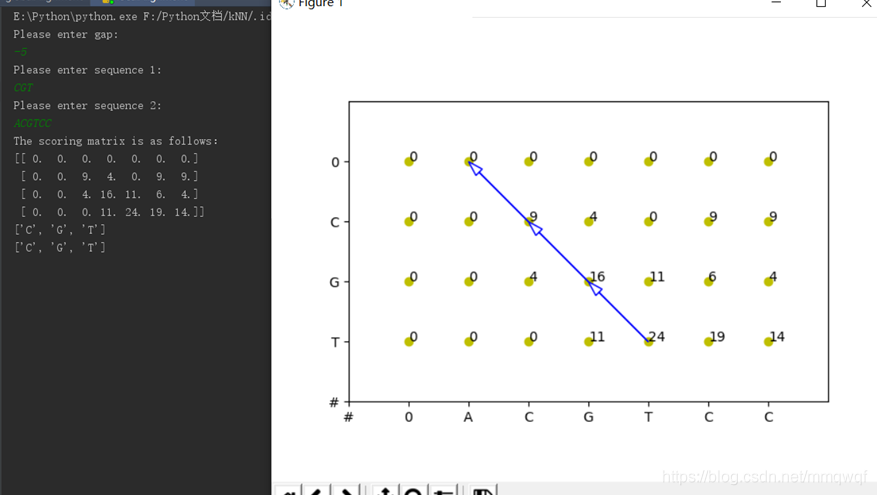
二、实验结果截图
1.全局比对



2.局部比对


到此这篇关于详解基于python的全局与局部序列比对的实现(DNA)的文章就介绍到这了,更多相关python全局与局部序列比对内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
总结
本次实验使用动态规划对全局序列比对进行了实现,自己卡的最久的地方是回溯以及画图的时候。刚开始在实现回溯的过程中,老是找不准回溯的条件以及将所有的路径都记录下来的方法,最后是使用的方向矩阵,也就是重新定义一个与得分矩阵等大的矩阵(但是这个矩阵是三维),存放的是每个位置能够回溯的方向,第一个数值表示左边,第二个表示左上,第三个表示上方,为0时表示当前方向不能回溯,没有路径,为1时表示能回溯,当该位置的所有能走的方向都走完时即可返回。将所有路径记录下来的方法是定义全局变量,当有路径能够走到终点时便将这条路径存放入该全局变量中。
绘图的时候使用的是matplotlib中的散点图,然后将每个点的得分以注释的形式标记在该点的右上角,并用箭头将路径绘出。不得不说的是,这个图确实太丑了,我学识浅薄,也没想到能画出这个图的更好的方法,还希望老师指点。
总的来说这次实验经历的时间还比较长,主要是因为python也没有很熟悉,很多函数也是查了才知道,然后可视化更是了解的少,所以画出来的图出奇的丑,还有回溯的时候也是脑子转不过弯来,所以要学习的东西还有很多,需要更加努力。
本次实验还能够有所改进的地方是:
1.把两个比对算法结合,让用户能够选择使用哪种比对方式。
2.作出一个更好看的界面,增加用户体验感。
3.把图画的更美观。
(老丁已阅,USC的同学们谨慎借鉴)
相关推荐
-
详解Python中的序列化与反序列化的使用
学习过marshal模块用于序列化和反序列化,但marshal的功能比较薄弱,只支持部分内置数据类型的序列化/反序列化,对于用户自定义的类型就无能为力,同时marshal不支持自引用(递归引用)的对象的序列化.所以直接使用marshal来序列化/反序列化可能不是很方便.还好,python标准库提供了功能更加强大且更加安全的pickle和cPickle模块. cPickle模块是使用C语言实现的,所以在运行效率上比pickle要高.但是cPickle模块中定义的类型不能被继承(其实大多数时候,我们
-
Python 序列化 pickle/cPickle模块使用介绍
Python序列化的概念很简单.内存里面有一个数据结构,你希望将它保存下来,重用,或者发送给其他人.你会怎么做?这取决于你想要怎么保存,怎么重用,发送给谁.很多游戏允许你在退出的时候保存进度,然后你再次启动的时候回到上次退出的地方.(实际上,很多非游戏程序也会这么干)在这种情况下,一个捕获了当前进度的数据结构需要在你退出的时候保存到硬盘上,接着在你重新启动的时候从硬盘上加载进来. Python标准库提供pickle和cPickle模块.cPickle是用C编码的,在运行效率上比pickle要高,
-
详解python中executemany和序列的使用方法
详解python中executemany和序列的使用方法 一 代码 import sqlite3 persons=[ ("Jim","Green"), ("Hu","jie") ] conn=sqlite3.connect(":memory:") conn.execute("CREATE TABLE person(firstname,lastname)") conn.executeman
-
浅析Python中的序列化存储的方法
在程序运行的过程中,所有的变量都是在内存中,比如,定义一个dict: d = dict(name='Bob', age=20, score=88) 可以随时修改变量,比如把name改成'Bill',但是一旦程序结束,变量所占用的内存就被操作系统全部回收.如果没有把修改后的'Bill'存储到磁盘上,下次重新运行程序,变量又被初始化为'Bob'. 我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshal
-
python时间日期函数与利用pandas进行时间序列处理详解
python标准库包含于日期(date)和时间(time)数据的数据类型,datetime.time以及calendar模块会被经常用到. datetime以毫秒形式存储日期和时间,datetime.timedelta表示两个datetime对象之间的时间差. 下面我们先简单的了解下python日期和时间数据类型及工具 给datetime对象加上或减去一个或多个timedelta,会产生一个新的对象 from datetime import datetime from datetime impo
-
Python的Django REST框架中的序列化及请求和返回
序列化Serialization 1. 设置一个新的环境 在我们开始之前, 我们首先使用virtualenv要创建一个新的虚拟环境,以使我们的配置和我们的其他项目配置彻底分开. $mkdir ~/env $virtualenv ~/env/tutorial $source ~/env/tutorial/bin/avtivate 现在我们处在一个虚拟的环境中,开始安装我们的依赖包 $pip install django $pip install djangorestframework $pip i
-

Python时间序列处理之ARIMA模型的使用讲解
ARIMA模型 ARIMA模型的全称是自回归移动平均模型,是用来预测时间序列的一种常用的统计模型,一般记作ARIMA(p,d,q). ARIMA的适应情况 ARIMA模型相对来说比较简单易用.在应用ARIMA模型时,要保证以下几点: 时间序列数据是相对稳定的,总体基本不存在一定的上升或者下降趋势,如果不稳定可以通过差分的方式来使其变稳定. 非线性关系处理不好,只能处理线性关系 判断时序数据稳定 基本判断方法:稳定的数据,总体上是没有上升和下降的趋势的,是没有周期性的,方差趋向于一个稳定的值. A
-
python计算一个序列的平均值的方法
本文实例讲述了python计算一个序列的平均值的方法.分享给大家供大家参考.具体如下: def average(seq, total=0.0): num = 0 for item in seq: total += item num += 1 return total / num 如果序列是数组或者元祖可以简单使用下面的代码 def average(seq): return float(sum(seq)) / len(seq) 希望本文所述对大家的Python程序设计有所帮助.
-
详解基于python的全局与局部序列比对的实现(DNA)
程序能实现什么 a.完成gap值的自定义输入以及两条需比对序列的输入 b.完成得分矩阵的计算及输出 c.输出序列比对结果 d.使用matplotlib对得分矩阵路径的绘制 一.实现步骤 1.用户输入步骤 a.输入自定义的gap值 b.输入需要比对的碱基序列1(A,T,C,G)换行表示输入完成 b.输入需要比对的碱基序列2(A,T,C,G)换行表示输入完成 输入(示例): 2.代码实现步骤 1.获取到用户输入的gap,s以及t 2.调用构建得分矩阵函数,得到得分矩阵以及方向矩阵 3.将得到的得分矩
-
详解基于python的图像Gabor变换及特征提取
1.前言 在深度学习出来之前,图像识别领域北有"Gabor帮主",南有"SIFT慕容小哥".目前,深度学习技术可以利用CNN网络和大数据样本搞事情,从而取替"Gabor帮主"和"SIFT慕容小哥"的江湖地位.但,在没有大数据和算力支撑的"乡村小镇"地带,或是对付"刁民小辈","Gabor帮主"可以大显身手,具有不可撼动的地位.IT武林中,有基于C++和OpenCV,或
-
详解基于python的多张不同宽高图片拼接成大图
半年前写过一篇将多张图片拼接成大图的博客,是讲的把所有图片先转换为256×256的图片后再进行拼接,今天看到一个朋友的评论说如何拼接非正方形图片,如47×57,之前有个朋友也问过这个,我当时理解错了,以为是要把不同尺寸的照片如32×45.56×75等拼接成大图,当时还纳闷,那不是很难看吗,还得填充非图片元素,emmm,只怪当年太天真.. 于是乎搞了下非方形图片的拼接,上代码: #!/usr/bin/env python # -*- coding:utf-8 -*- import PIL.Imag
-
基于YUV 数据格式详解及python实现方式
YUV 数据格式概览 YUV 的原理是把亮度与色度分离,使用 Y.U.V 分别表示亮度,以及蓝色通道与亮度的差值和红色通道与亮度的差值.其中 Y 信号分量除了表示亮度 (luma) 信号外,还含有较多的绿色通道量,单纯的 Y 分量可以显示出完整的黑白图像.U.V 分量分别表示蓝 (blue).红 (red) 分量信号,它们只含有色彩 (chrominance/color) 信息,所以 YUV 也称为 YCbCr,C 意思可以理解为 (component 或者 color). 维基百科上的 RGB
-
详解基于Android的Appium+Python自动化脚本编写
1.Appium Appium是一个开源测试自动化框架,可用于原生,混合和移动Web应用程序测试, 它使用WebDriver协议驱动iOS,Android和Windows应用程序. 通过Appium,我们可以模拟点击和屏幕的滑动,可以获取元素的id和classname,还可以根据操作生成相关的脚本代码. 下面开始Appium的配置. appPackage和APPActivity的获取 任意下载一个app 解压 但是解压出来的xml文件可能是乱码,所以我们需要反编译文件. 逆向AndroidMan
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
详解基于Jupyter notebooks采用sklearn库实现多元回归方程编程
一.导入excel文件和相关库 import pandas; import matplotlib; from pandas.tools.plotting import scatter_matrix; data = pandas.read_csv("D:\\面积距离车站.csv",engine='python',encoding='utf-8') 显示文件大小 data.shape data 二.绘制多个变量两两之间的散点图:scatter_matrix()方法 #绘制多个变量两两之间的
-
详解基于Scrapy的IP代理池搭建
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
详解基于Facecognition+Opencv快速搭建人脸识别及跟踪应用
人脸识别技术已经相当成熟,面对满大街的人脸识别应用,像单位门禁.刷脸打卡.App解锁.刷脸支付.口罩检测........ 作为一个图像处理的爱好者,怎能放过人脸识别这一环呢!调研开搞,发现了超实用的Facecognition!现在和大家分享下~~ Facecognition人脸识别原理大体可分为: 1.通过hog算子定位人脸,也可以用cnn模型,但本文没试过: 2.Dlib有专门的函数和模型,实现人脸68个特征点的定位.通过图像的几何变换(仿射.旋转.缩放),使各个特征点对齐(将眼睛.嘴等部位移
-
详解基于pycharm的requests库使用教程
目录 requests库安装和导入 requests库的get请求 requests库的post请求 requests库的代理 requests库的cookie 自动识别验证码 requests库安装和导入 第一步:cmd打开命令行,使用如下命令安装requests库. pip install requests 由于我的安装过了,所以如下: 如果提示你pip版本需要更新,按照提示的指令输入即可更新. 第二步:cmd使用如下命令,验证requests库安装完成. pip list 第三步:在pyc